Is PREEMPT_RT Enough? Validating Real-Time Performance on Jetson Orin
Engineers looking to deploy robot control systems on Jetson have likely asked themselves this question at some point:
"Is installing the PREEMPT_RT kernel enough for 1kHz control? Or do I need to build a custom kernel?"
In this article, we validate with measured data whether NVIDIA's official RT package + CPU isolation alone can meet the latency requirements for 1kHz EtherCAT control on a Jetson Orin AGX.
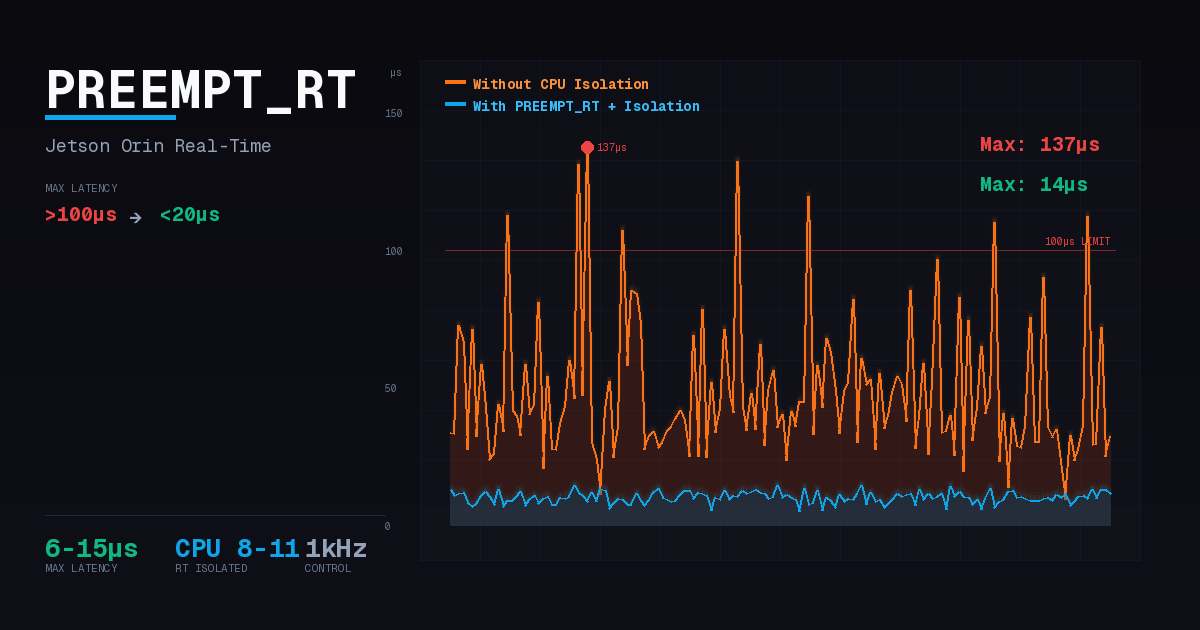
The conclusion upfront: PREEMPT_RT alone is not enough. Without CPU isolation, abnormal jitter spikes exceeding 100us frequently occurred under GPU, Storage, and EtherCAT loads. PREEMPT_RT + CPU isolation together were required to achieve max latency below 20us under all load conditions.
1kHz Control and Latency Requirements
Why 100us?
A 1kHz control loop operates at a 1ms (1000us) period. The following tasks must execute sequentially in each cycle:
- Wakeup - RT task is awakened by the scheduler
- Read - Receive EtherCAT frame, read sensor data
- Compute - Control algorithm computation (PID, inverse kinematics, etc.)
- Write - Send motor commands
All these tasks must complete within 1ms to not miss the next cycle. Generally, wakeup latency should be 10% or less of the period to ensure sufficient time for remaining tasks. Therefore, the wakeup latency target for 1kHz control is 100us.
Why EtherCAT Communication is Vulnerable
The EtherCAT master periodically sends and receives frames. Problems that occur during this process:
- Interrupt interference: Interrupts from NVMe, GPU, network, etc. preempting RT tasks delays frame transmission timing
- Scheduling delays: If kernel threads (ksoftirqd, kworker, etc.) execute before RT tasks, wakeup is delayed
- DC synchronization issues: EtherCAT Distributed Clocks compensate for master jitter to some extent, but severe delays cause missed deadlines for next cycle frame transmission, resulting in missed control loop data updates. DC provides sub-1us synchronization between slaves, but master-side timing must be managed separately
This can ultimately lead to motor torque output delays, increased position tracking errors, and in severe cases, control loop divergence.
Reference Research
Research measuring EtherCAT control performance in ROS2 environments (ROS2 Performance Study, 2023) reported average 2us, maximum 82us latency. These figures meet the 1kHz control criterion (100us).
Test Goals and Environment
Test Goals
As explained earlier, EtherCAT masters are vulnerable to interrupts and scheduling. The PREEMPT_RT kernel alone cannot completely block such interference. CPU isolation secures dedicated cores for RT tasks, ensuring most system activities (GPU rendering, NVMe I/O, general kernel threads, etc.) do not execute on those cores. However, some exceptions remain such as IPI (inter-processor interrupts), local timers, and per-CPU kernel threads.
Core question: Is NVIDIA OTA RT package + CPU isolation sufficient for 1kHz control loops?
This test validates whether wakeup latency remains stable without spikes exceeding 100us even when various system loads occur with CPUs 8-11 isolated.
Test Environment
| Item | Specification |
|---|---|
| Hardware | Jetson Orin AGX 64GB |
| Kernel | NVIDIA RT Package (OTA) |
| Power Mode | MAXN + jetson_clocks |
| Test Duration | 10 minutes (600,000 samples) |
| Measurement Tool | cyclictest -p 80 -i 1000 -l 600000 -m -a 8-11 |
| RT Throttling | Disabled (sched_rt_runtime_us=-1) |
| Success Criterion | All tests Max latency < 100us |
Effect of RT Kernel
First, let's verify the effect of the RT kernel itself. Under combined load (CPU + I/O + Memory):
| Kernel | Max Latency | Note |
|---|---|---|
| non-RT (stock) | 318us | Exceeds 100us criterion |
| RT (PREEMPT_RT) | 56us | 82% improvement |
PREEMPT_RT alone improves from 318us to 56us - an 82% improvement. While this meets the 100us criterion for simple stress-ng combined loads, we cannot conclude "real-time control is possible" from this alone.
In actual operating environments, various loads occur including GPU rendering, NVMe I/O, and EtherCAT communication. Testing under these real load conditions reveals frequent abnormal jitter spikes with PREEMPT_RT alone.
How PREEMPT_RT Works
The PREEMPT_RT patch transforms the standard Linux kernel into a fully preemptible kernel. Key changes:
Threaded IRQ (Interrupt Threading)
In the standard kernel, interrupt handlers execute in interrupt context where the scheduler cannot intervene. PREEMPT_RT converts most interrupt handlers into kernel threads (irq/N-name), making them scheduling targets.
IRQ threads run by default at SCHED_FIFO priority 50. Therefore, RT tasks with higher priority (e.g., 80) can be scheduled before IRQ threads. However, top-half (hardirq) still executes in interrupt context, and interrupts marked with IRQF_NO_THREAD (timers, IPI, etc.) are not threaded.
Priority Inheritance
Priority inversion is a classic problem in real-time systems:
- Low-priority task (L) acquires a lock
- High-priority RT task (H) requests the same lock and waits
- Medium-priority task (M) preempts L - H runs later than M
PREEMPT_RT's RT-Mutex implements priority inheritance. When L holds a lock and H waits, L's priority temporarily matches H's, preventing M from preempting L. L reverts to its original priority when releasing the lock.
This mechanism became essential for real-time systems after the Mars Pathfinder mission in 1997 experienced system resets due to priority inversion.
Spinlock to RT-Mutex Conversion
The standard kernel's spin_lock is implemented with busy-waiting. It occupies the CPU while waiting for lock release, preventing other tasks from executing.
PREEMPT_RT converts most spin_locks to sleepable RT-mutexes:
| Aspect | Standard Kernel (spinlock) | PREEMPT_RT (RT-mutex) |
|---|---|---|
| Wait Method | Busy-waiting (CPU occupied) | Sleep (CPU yielded) |
| Preemptible | No | Yes |
| Priority Inheritance | No | Yes |
However, raw_spin_lock remains unconverted as original spinlocks. These are used in minimal sections requiring interrupt disabling (hardware register access, etc.).
This enables preemption during kernel critical sections protected by RT-mutex, greatly reducing the time high-priority RT tasks are blocked by low-priority kernel work.
PREEMPT_RT Limitations
PREEMPT_RT is powerful but does not solve all jitter causes:
| Jitter Cause | PREEMPT_RT Solution | Additional Action Needed |
|---|---|---|
| Interrupt handler delay | Threaded IRQ | - |
| Priority inversion | Priority Inheritance | - |
| Kernel critical section | RT-Mutex | - |
| Interrupt location | No | irqaffinity needed |
| Cache pollution | No | isolcpus needed |
| Kernel thread contention | No | kthread_cpus needed |
| Timer ticks | No | nohz_full needed (not in OTA) |
PREEMPT_RT guarantees "if an RT task can run, it runs immediately" but does not guarantee "interference is prevented from accessing the CPU where the RT task runs." This is the fundamental reason why CPU isolation is needed.
Why CPU Isolation is Needed
Even with the RT kernel installed, latency spikes occur under certain load conditions without CPU isolation. To understand this phenomenon, we need to examine the OS's interrupt handling, cache architecture, and scheduling mechanisms.
Root Causes of Jitter
In real-time control, "jitter" refers to execution time variation of periodic tasks. Even with low average latency, intermittent abnormal spikes mean proper real-time control is not possible.
Key reasons jitter spikes occur even with PREEMPT_RT kernel:
1. Interrupt Interference
The Linux kernel divides interrupt processing into two stages:
- Top-half (hardirq): Executes immediately upon IRQ occurrence. Performs minimal processing like hardware ACK with interrupts disabled
- Bottom-half: Actual data processing. In PREEMPT_RT, executes as kernel thread (
irq/N-name) and is preemptible
The problem is top-half still executes in interrupt context. When NVMe I/O, GPU, or network interrupts occur, however brief, the RT task must wait until top-half completes.
Thanks to PREEMPT_RT's threaded IRQ, bottom-half becomes a scheduling target, but which CPU processes interrupts depends on IRQ affinity settings. Without isolation, top-half can execute on the core where RT tasks are running.
2. Cache Pollution
Modern CPUs use multi-level caches (L1/L2/L3) to speed up memory access. When an RT task is preempted:
- Another process/kernel thread executes on the CPU
- That process's data is loaded into cache - RT task's cache lines are evicted
- When the RT task resumes, cache miss occurs
- Main memory access needed - tens to hundreds of cycles delay
This same phenomenon occurs with TLB (Translation Lookaside Buffer). TLB misses trigger page table walks, causing additional delays.
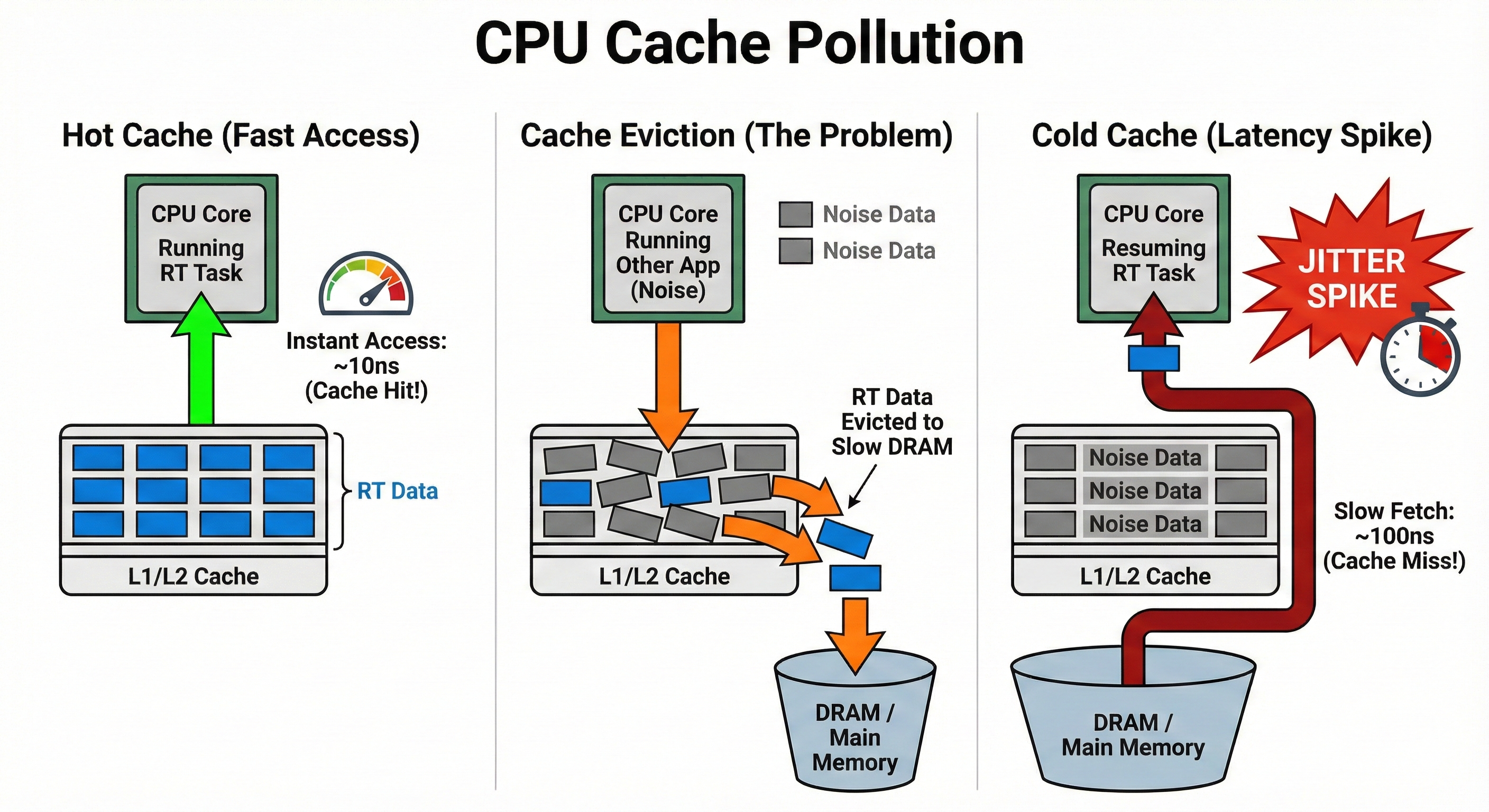
Hot Cache (~10ns) -> Cache Eviction -> Cold Cache (~100ns): 10x delay from cache miss causes jitter spikes
3. Kernel Thread Contention
The Linux kernel handles various background tasks through kernel threads:
| Kernel Thread | Role | Impact on RT Tasks |
|---|---|---|
ksoftirqd | Soft interrupt processing (network, timers) | Batch processing delays when softirq delayed |
kworker | Async kernel work queue processing | Executes at unpredictable times |
rcu_preempt | RCU callback processing | Runs periodically on all CPUs |
migration | Task movement between CPUs | Migrated tasks start with cold cache |
These threads can run on any CPU by default and compete with RT tasks.
4. Timer Tick Overhead
The default Linux kernel generates periodic timer interrupts (ticks) on all CPUs. Each tick involves:
- Interrupt handler execution
- Scheduler invocation (runqueue check)
- Time-related statistics updates
- RCU callback checks
This overhead is typically a few microseconds, but combined with other factors, it can lead to spikes. The nohz_full option removes these ticks on isolated CPUs, but is not included in NVIDIA's OTA RT package.
How CPU Isolation Works
CPU isolation acts on several kernel subsystems simultaneously. Let's examine how each parameter works at the kernel level.
isolcpus: Exclusion from Scheduler Domains
isolcpus=domain,8-11 excludes CPUs 8-11 from the kernel scheduler's load balancing targets:
# Check /sys/devices/system/cpu/cpu8/domain*
# Isolated CPUs have their own single-CPU domain
The kernel scheduler periodically redistributes tasks between CPUs (load balancing). Isolated CPUs are excluded from this process:
- Regular processes are not automatically placed on them
- RT tasks' L1/L2 cache and TLB are not polluted (LLC/L3 is shared and can still be affected)
- Only tasks explicitly specified with
tasksetorsched_setaffinity()execute
isolcpus has the constraint that it cannot be changed after boot, so cgroup/cpuset is recommended for environments needing runtime flexibility. However, in real-time/embedded systems, isolcpus provides more reliable isolation. NVIDIA's official RT kernel documentation also recommends isolcpus=managed_irq,domain.
irqaffinity: Interrupt Routing Control
irqaffinity=0-7 sets the default affinity of all IRQs to CPUs 0-7 at kernel boot:
# Check after boot
cat /proc/irq/*/smp_affinity_list
# Most device IRQs set to 0-7 (per-CPU/managed IRQs are exceptions)
This setting changes the default value of /proc/irq/<irq>/smp_affinity. However, userspace drivers or irqbalance can change this at runtime, so in production environments, disabling irqbalance or locking settings is recommended.
kthread_cpus: Kernel Thread Isolation
kthread_cpus=0-7 restricts default CPU affinity when creating kernel threads:
# Check after boot
ps -eo pid,comm,psr | grep -E 'ksoftirqd|kworker|rcu'
# Most kernel threads run on CPU 0-7
However, not all kernel threads follow this setting. Some per-CPU kernel threads (e.g., migration/N, cpuhp/N) are bound to specific CPUs and cannot be moved. These threads still run on isolated CPUs, but their execution frequency is low, so actual impact is minimal.
Synergy of the Three Parameters
| Layer | Parameter | Isolation Target |
|---|---|---|
| Scheduler | isolcpus=domain | Regular processes |
| Interrupts | irqaffinity | Hardware interrupts |
| Kernel | kthread_cpus | Kernel background threads |
All three parameters must be used together for complete isolation. Setting only isolcpus isolates processes but interrupts and kernel threads can still invade RT cores.
Average vs Worst-Case Latency
What matters in real-time systems is worst-case, not average latency.
| Metric | Meaning | Impact on 1kHz Control |
|---|---|---|
| Average Latency | Performance in most cases | General control quality |
| Worst-Case Latency | Performance in worst case | Control failure if exceeded even once |
In robot control, jitter spikes lead to motor torque output delays, missed sensor feedback, and control loop instability.
Results from 10-minute tests (600,000 samples) without isolation:
| Load | Avg Latency | Max Latency | Verdict |
|---|---|---|---|
| Idle | 2.4us | 22us | PASS |
GPU (glmark2) | 3.6us | 159us | FAIL |
| EtherCAT (1kHz DC) | 3.8us | 113us | FAIL |
Storage (fio) | 5.3us | 145us | FAIL |
System (stress-ng) | 6.1us | 47us | PASS |
Average latency is good at under 10us for all, but Max latency spikes exceeding 100us occurred under GPU, EtherCAT, and Storage loads. Repeated spikes lead to degraded control quality and are unacceptable in applications requiring precision control.
CPU Isolation Configuration
We applied the following boot parameters to isolate CPUs 8-11 for RT use:
| Parameter | Role |
|---|---|
isolcpus=managed_irq,domain,8-11 | Scheduler isolation + managed IRQ isolation |
irqaffinity=0-7 | Restrict general IRQs to CPU 0-7 |
kthread_cpus=0-7 | Restrict kernel threads to CPU 0-7 |
isolcpus alone is incomplete. The managed_irq flag only isolates IRQs automatically managed by the kernel (MSI-X, NVMe, etc.), so irqaffinity and kthread_cpus must be used together for complete isolation of general IRQs and kernel threads.
Application-Level Optimization
Kernel settings alone are insufficient. The RT task itself must also be properly configured to achieve real-time performance.
RT Scheduling Policy Configuration
Linux provides several scheduling policies:
| Policy | Priority | Characteristics |
|---|---|---|
SCHED_OTHER | (none) | Default policy, always preempted by RT tasks |
SCHED_FIFO | 1-99 | RT policy, higher priority preempts lower |
SCHED_RR | 1-99 | RT policy, FIFO + time-slicing among same priority |
SCHED_FIFO is suitable for 1kHz control tasks. Without time-slicing, the task runs until it yields (sched_yield) or is preempted by higher priority, making behavior deterministic.
Three Elements of RT Task Configuration
For an RT task to operate deterministically, three things must be configured:
| Setting | API / Command | Purpose |
|---|---|---|
| Memory Lock | mlockall() | Prevent ms-level delays from page faults |
| CPU Affinity | sched_setaffinity() or taskset | Execute only on isolated CPUs |
| RT Scheduling | sched_setscheduler() | Apply SCHED_FIFO policy |
Order matters:
mlockall()- Process page faults before RT scheduling is applied- CPU affinity - Bind to isolated CPUs
sched_setscheduler()- Apply RT policy last
The reason to call mlockall() first: Page faults can occur when loading memory pages, and after RT scheduling is applied, this delay directly impacts the control loop.
- Stack extension preparation:
mlockall()locks currently allocated stack, but stack extension can cause page faults on new pages. Prefault the stack by declaring a sufficiently large local array before entering the RT loop. - Memory capacity check: Since all memory is pinned to physical RAM, the OOM killer may terminate other processes if system memory is insufficient.
Results After CPU Isolation
Re-measurement under the same load conditions after CPU isolation:
| Load | Before (Max) | After (Max) | Improvement |
|---|---|---|---|
| Idle | 22us | 8us | 64% |
| GPU | 159us (FAIL) | 15us (PASS) | 91% |
| EtherCAT | 113us (FAIL) | 6us (PASS) | 95% |
| Storage | 145us (FAIL) | 7us (PASS) | 95% |
| System | 47us | 15us | 68% |
The three tests that FAILED before isolation (GPU, EtherCAT, Storage) all converted to PASS. No spikes exceeding 100us were observed during the test period (10 minutes/600k samples), and all tests achieved max latency below 20us. These figures have sufficient margin from the 1kHz control criterion (100us).
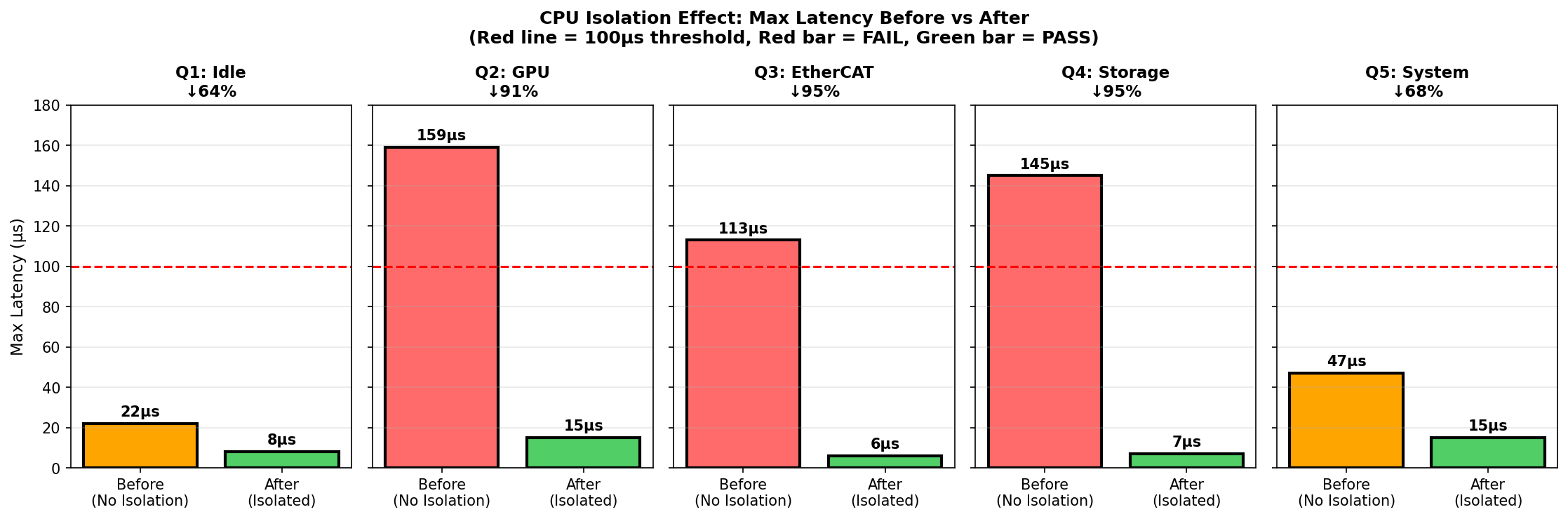
Red bars: Exceeds 100us (FAIL), Green bars: Below 100us (PASS), Dotted line: 100us criterion
Time Series Distribution Comparison
Comparing latency distributions measured over 10 minutes makes the isolation effect clearer:
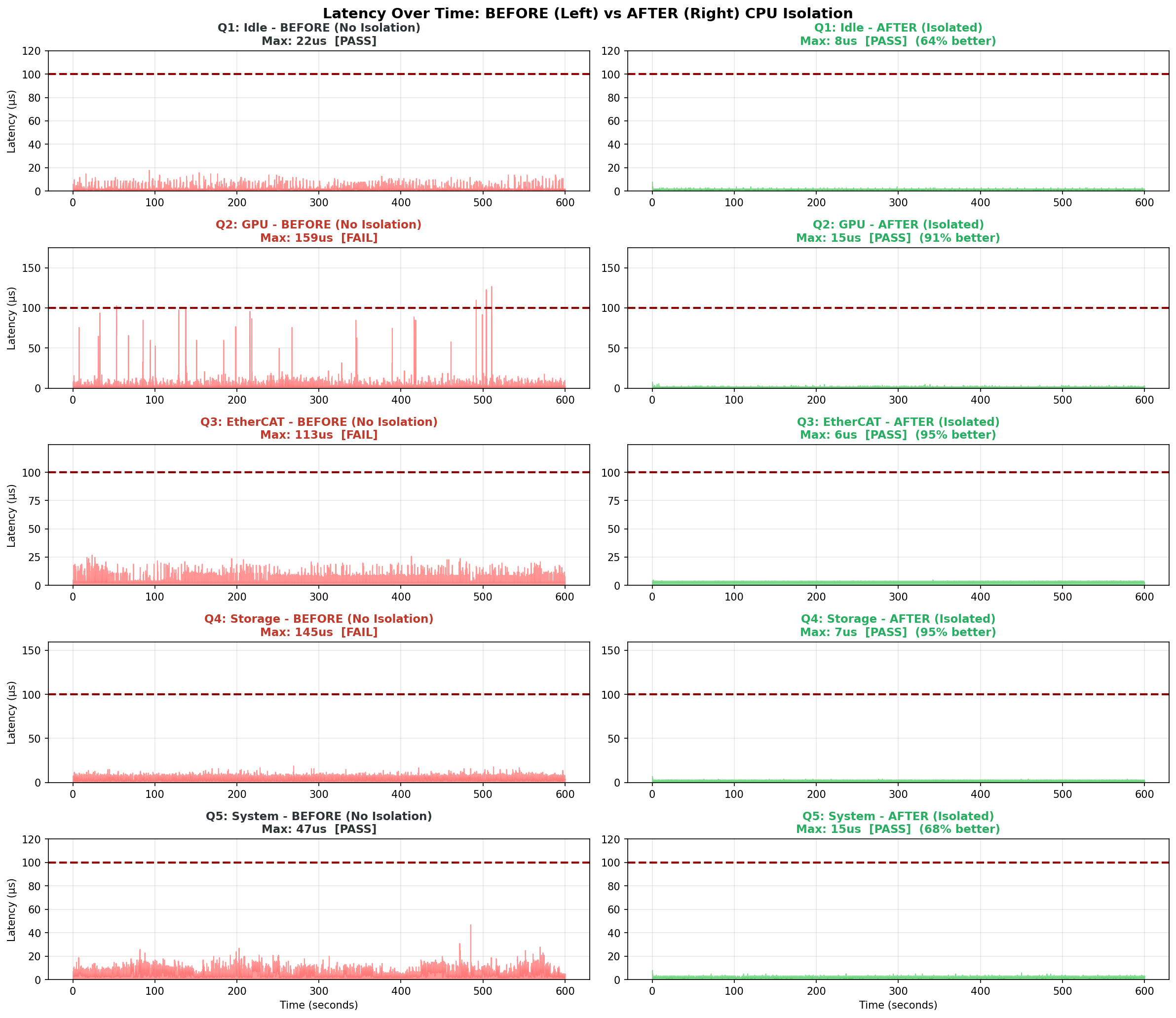
Without isolation (left), spikes occasionally exceed 100us. While average latency looks good, multiple such spikes were observed even in 10-minute tests.
With isolation (right), all measured samples remained stable below 15us. This is the essence of "real-time control" - managing worst-case, not average.
Custom Kernel Exploration Process
The Q-test results shown earlier used the NVIDIA OTA RT package. However, we also explored custom kernel builds to verify whether the nohz_full and rcu_nocbs options recommended by industry standards are truly necessary.
Why We Considered Custom Builds
Linux Kernel official documentation, Intel ECI SDK, Red Hat RT and others recommend the following options for real-time systems:
CONFIG_NO_HZ_FULL: Remove timer ticks on isolated CPUsCONFIG_RCU_NOCB_CPU: Offload RCU callbacks to other CPUs
The NVIDIA OTA RT package does not include these options. Therefore, setting nohz_full=8-11, rcu_nocbs=8-11 as boot parameters is ignored.
Custom Kernel Build Tests (M-tests)
We built a custom kernel (CONFIG_NO_HZ_FULL=y, CONFIG_RCU_NOCB_CPU=y) and tested under Idle and combined load (L2: CPU + I/O + Memory) conditions:
| Condition | Kernel | Isolation | Load | Max Latency | Status |
|---|---|---|---|---|---|
| M1 | non-RT | No | Idle | 53us | PASS |
| M2 | non-RT | No | L2 | 318us | FAIL |
| M3 | RT | No | Idle | 23us | PASS |
| M4 | RT | No | L2 | 56us | PASS |
| M5 | RT | Yes | Idle | 26us | PASS |
| M6 | RT | Yes | L2 | 24us | PASS |
M-tests isolation boot parameters:
isolcpus=managed_irq,domain,8-11 nohz_full=8-11 rcu_nocbs=8-11 rcu_nocb_poll irqaffinity=0-7 kthread_cpus=0-7
Step-by-Step Improvement Effect
| Step | Change | Improvement |
|---|---|---|
| non-RT -> RT (load) | 318us -> 56us | 82% reduction |
| RT -> RT+isolation (load) | 56us -> 24us | 57% reduction |
| Total (M2 -> M6) | 318us -> 24us | 92% reduction |
Significance of M-tests
M-tests and Q-tests cannot be directly compared:
- M-tests: Exploratory tests, stress-ng L2 load only, 1 minute
- Q-tests: Production validation, individual GPU/EtherCAT/Storage loads, 10 minutes (600,000 samples)
Therefore, comparing "M6 (24us) vs Q-tests (6-15us)" to conclude "OTA is better" is not valid.
What M-tests show:
- PREEMPT_RT effect: 82% improvement from non-RT (318us) to RT (56us)
- CPU isolation additional effect: 57% additional improvement from RT (56us) to RT+isolation (24us)
- Custom kernel (NO_HZ_FULL) achieves 24us: Sufficiently meets 100us criterion
What Q-tests show:
- OTA package + CPU isolation achieves 6-15us: Also meets 100us criterion
- Validated under various real loads (GPU, Storage, EtherCAT)
Conclusion: Both approaches meet 1kHz control requirements (100us). However, the OTA package is easy to install, while custom builds are complex. Additional experiments are needed to verify performance differences under identical conditions.
When Custom Kernel Build is Necessary
Based on JetPack 6.2 (L4T 36.x), the OTA RT package does not include the following options:
CONFIG_NO_HZ_FULL(Full dynticks)CONFIG_RCU_NOCB_CPU(RCU callback offloading)
These options are recommended by Linux Kernel official documentation for the following cases:
"Unless you are running realtime applications or certain types of HPC workloads, you will normally NOT want this option"
When custom build is needed:
- When PREEMPT_RT's worst-case latency (~100us) is still insufficient
- High-frequency trading (HFT), semiconductor equipment control, and other extreme latency requirements
When choosing custom kernel builds, consider the following:
- Build time: 60-90 minutes required (OTA is 5-10 minutes)
- NVMe rootfs boot caution: If NVMe driver is a module (=m) and not included in initrd, boot fails. Built-in (=y) is safest
- initrd sync required: Manual
/boot/initrdupdate needed after kernel build. Most common boot failure cause
The OTA package is sufficient for most robot control applications.
Q-tests achieved 6-15us max latency with OTA package + CPU isolation, and M-tests achieved 24us with custom kernel. While direct comparison is difficult due to different test conditions, both sufficiently meet the 100us criterion.
Currently (December 2025) JetPack 7 has been released exclusively for Jetson Thor, and Orin series is not yet officially supported. JetPack 6 for Orin is the current production version. However, JetPack 7 official documentation mentions CONFIG_NO_HZ_FULL and CONFIG_RCU_NOCB_CPU related settings, suggesting these options may be included in the OTA RT package when JetPack 7 for Orin is released.
Custom Build Trade-offs
If considering custom builds, be aware of the following trade-offs:
| Aspect | Isolated CPUs | Entire System |
|---|---|---|
| Latency | Improved | - |
| Housekeeping CPU load | - | Increased |
| Syscall overhead | Increased | Increased |
| Throughput | - | Decreased |
SUSE Labs analysis:
"The jitter-free power you gain on your set of isolated CPUs comes at the expense of more work for the other CPUs"
Key Takeaways
The answer to "Is PREEMPT_RT enough?":
No. PREEMPT_RT alone produces jitter spikes exceeding 100us under GPU, Storage, and EtherCAT loads. CPU isolation is mandatory, not optional.
Required configuration for 1kHz EtherCAT control:
- NVIDIA official RT package (OTA)
- CPU isolation:
isolcpus+irqaffinity+kthread_cpus(mandatory)
Results with PREEMPT_RT + CPU isolation:
- Max latency 6-15us achieved under all load conditions (sufficient margin from 100us criterion)
- 91-95% jitter improvement under GPU, Storage, EtherCAT loads
Custom kernel builds are unnecessary for most robot control applications. However, if you install only PREEMPT_RT and operate without CPU isolation, abnormal jitter may occur under real load conditions.
References
Official Documentation
- NVIDIA Real-Time Kernel Guide (L4T 36.x)
- Ubuntu - Real-time kernel tuning
- Linux Kernel - NO_HZ Documentation
CPU Isolation Deep Dive
Jetson Kernel Build
- NVIDIA Kernel Customization (L4T 36.x)
- Jetson Orin Boot Flow - Understanding boot architecture
- UEFI Adaptation - extlinux.conf configuration