MotoROS2 Point Queue Proxy Server
MotoROS2의 200포인트 궤적 제한을 해결하고 수천 개 포인트의 정밀 궤적을 끊김 없이 실행하는 방법. Micro-ROS의 구조적 한계와 QueueTrajPoint 서비스의 데이터 유실 문제를 동시에 극복한 Proxy Server 설계 사례를 공유합니다.
문제 상황: MotoROS2의 구조적 한계
Yaskawa 산업용 로봇을 ROS 2 환경에서 운용하려면 공식 드라이버인 MotoROS2가 필수입니다. MotoROS2는 로봇 모션 제어를 위해 두 가지 인터페이스를 제공합니다:
| 인터페이스 | 방식 | 용도 |
|---|---|---|
FollowJointTrajectory Action | Batch 전송 | 전체 궤적을 한 번에 전송 |
QueueTrajPoint Service | Point-by-Point | 포인트를 하나씩 순차 전송 |
정밀 용접, 3D 프린팅 경로, 복잡한 조립 공정처럼 수천 개의 포인트로 이루어진 고해상도 궤적이 필요한 어플리케이션에서는 두 방식 모두 심각한 한계에 직면합니다.
MotoROS2 아키텍처 이해
문제의 근본 원인을 파악하려면 MotoROS2의 내부 아키텍처를 이해해야 합니다.
핵심 구성요소:
- Micro-ROS Agent: PC에서 실행되며 표준 ROS 2 DDS와 임베디드 환경의 XRCE-DDS를 중계
- MotoROS2: YRC1000 컨트롤러 내부에서 MotoPlus 애플리케이션으로 실행
- Motion API: 수신된 포인트를 4ms 단위로 보간(Interpolation)하여 서보에 전달
MotoROS2는 임베디드 환경에서 ROS 2 통신을 구현하기 위해 Micro-ROS를 사용합니다. 여기서 첫 번째 제약이 발생합니다.
Micro-ROS의 메모리 제약
Micro-ROS는 리소스 제약이 있는 마이크로컨트롤러를 위한 ROS 2 구현체입니다. 표준 Fast-DDS 대신 경량화된 Micro XRCE-DDS를 사용하며, 이로 인해 메시지 크기에 엄격한 제한이 존재합니다.
| 파라미터 | 기본값 | 설명 |
|---|---|---|
| MTU (Maximum Transmission Unit) | 512 bytes | 단일 전송 단위 크기 |
RMW_UXRCE_STREAM_HISTORY | 4~8 slots | Reliable 스트림 히스토리 |
| Maximum Message Size | ~64 KB | XRCE 프로토콜 한계 |
결과: FollowJointTrajectory 메시지에 포함할 수 있는 최대 포인트 수가 약 200개로 제한됩니다.
JointTrajectory 메시지 크기 ≈ N × (joints × 8 bytes × 4 + timestamp)
200 points × 6 joints × 32 bytes ≈ 38.4 KB (< 64 KB limit)
Problem 1: FollowJointTrajectory의 200포인트 한계
ROS 2의 trajectory_msgs/JointTrajectory 메시지 규격 자체에는 포인트 개수 제한이 없습니다. 하지만 Micro-ROS의 버퍼 제약으로 인해 MotoROS2에서는 하나의 트래젝토리에 약 200개가 상한선입니다.
실패 모드 분석
200개를 초과하는 메시지 전송 시 발생하는 현상:
증상:
- 메시지가 "void로 사라짐" (공식 GitHub Issue 표현)
- Action Server가 락업(Lock-up) 상태 진입
- Goal 수신 확인 불가
일반적인 우회 시도와 한계
1. 궤적 다운샘플링 (Downsampling)
# 2000개 → 200개로 축소
downsampled = trajectory[::10] # 10개당 1개만 선택
- 문제: 정밀도 저하. 고해상도가 필요한 공정에서 부적합
2. 궤적 분할 전송 (Chunking)
# 200개씩 나누어 순차 전송
for chunk in [trajectory[i:i+200] for i in range(0, len(trajectory), 200)]:
send_fjt_goal(chunk)
wait_for_completion() # 완료 대기
- 문제: Action 전환 시점에서 로봇이 멈칫거림(Stutter). 연속성 보장 불가
Problem 2: QueueTrajPoint 서비스의 BUSY 응답
MotoROS2는 200포인트 제한의 대안으로 queue_traj_point 서비스를 제공합니다. 이름과 달리 실제 내부 큐가 없습니다.
BUSY 응답 메커니즘
데이터 유실의 물리적 결과
포인트 이 BUSY로 폐기되고 클라이언트가 이를 재전송하지 않으면:
- 로봇은 에서 으로 직접 이동 시도
- 궤적에 불연속점(Discontinuity) 발생
- 급격한 위치 변화 → 모터 토크 과부하
결과:
- 물리적 충격으로 인한 기구부 손상 위험
- 컨트롤러 에러 및 비상 정지(E-Stop) 발생
- 공정 중단 및 생산성 저하
궤적 불연속의 수학적 분석
연속 궤적에서 위치 , 속도 , 가속도 의 연속성이 중요합니다:
포인트 유실 시, 컨트롤러는 다음 타임슬롯에서 을 목표로 삼습니다. 등간격 궤적()을 가정하면:
동일한 제어 주기 내에 약 2배의 거리를 이동해야 하므로, 요구 속도가 2배로 급증합니다.
로봇 동역학 관점에서 이는 급격한 토크 변화로 이어집니다:
가 급증하면 (관절 토크)도 급증하여 모터 보호 회로가 동작하거나 기구부에 충격이 가해집니다.
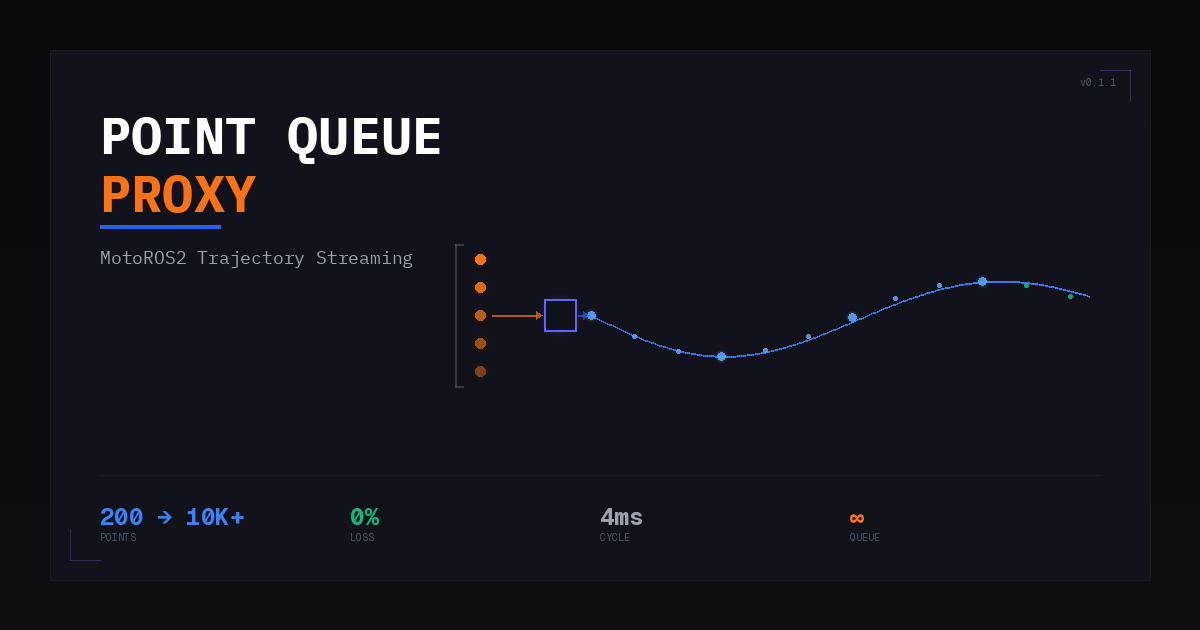
해결책: Point Queue Proxy Server
두 문제를 동시에 해결하기 위해 MoveIt2와 MotoROS2 사이에 중재자 역할을 하는 Proxy Server를 설계했습니다.
설계 목표
| 목표 | 설명 |
|---|---|
| Transparent Proxy | 상위 제어기(MoveIt2)는 일반 로봇 컨트롤러와 동일하게 사용 |
| Unlimited Trajectory | 포인트 수 제한 없이 궤적 수신 |
| Lossless Streaming | 모든 포인트가 순서대로, 유실 없이 로봇에 전달 |
| Continuous Motion | 연속 공정에서 끊김 없는 동작 |
시스템 아키텍처
인터페이스 설계:
-
Northbound (To Planner):
FollowJointTrajectoryAction Server- MoveIt2 등 상위 플래너로부터 전체 궤적을 Batch로 수신
- 포인트 수 제한 없음
-
Southbound (To Robot):
QueueTrajPointService Client- MotoROS2로 포인트를 하나씩 전송
- 흐름 제어(Flow Control) 적용
-
Feedback Loop:
/joint_statesSubscriber- 로봇의 실제 관절 위치 실시간 모니터링
- 동작 완료(Convergence) 판단
핵심 메커니즘 1: Reliable Streaming with Flow Control
TCP의 흐름 제어(Flow Control) 원리를 차용한 Smart Retry 메커니즘입니다.
핵심 파라미터:
| 파라미터 | 권장값 | 설명 |
|---|---|---|
busy_wait_time | 4~8 ms | 재시도 간 대기 시간 (모션 주기 기준) |
max_retries | 50~100 | 최대 재시도 횟수 |
service_timeout | 100 ms | 서비스 응답 타임아웃 |
흐름 제어 원리:
로봇 컨트롤러는 4ms 주기로 포인트를 소비합니다. Proxy Server는 BUSY 응답을 "소비자(Consumer)가 아직 처리 중" 신호로 해석하고, 적절한 딜레이 후 재전송합니다. 이는 TCP의 슬라이딩 윈도우와 유사한 생산자-소비자 속도 동기화입니다.
// Backpressure 기반 흐름 제어
int queue_point_with_retry(const trajectory_msgs::msg::JointTrajectoryPoint& point)
{
int attempt = 0;
while (rclcpp::ok() && attempt < max_retries_) {
auto request = std::make_shared<motoros2_interfaces::srv::QueueTrajPoint::Request>();
request->point = point;
auto future = queue_point_client_->async_send_request(request);
auto status = future.wait_for(service_timeout_);
if (status == std::future_status::timeout) {
RCLCPP_WARN(get_logger(), "Service timeout, attempt %d/%d",
attempt + 1, max_retries_);
++attempt;
std::this_thread::sleep_for(busy_wait_time_); // timeout 후에도 대기
continue;
}
auto result = future.get();
// BUSY가 아니면 결과 반환 (SUCCESS 또는 에러)
if (result->result_code != ResultCode::BUSY) {
return result->result_code;
}
// Backpressure: 소비자가 준비될 때까지 대기 후 재시도
++attempt;
std::this_thread::sleep_for(busy_wait_time_);
}
RCLCPP_ERROR(get_logger(), "Max retries (%d) exceeded", max_retries_);
return ResultCode::ERROR;
}
핵심 메커니즘 2: Goal Queueing
복잡한 공정에서는 여러 궤적을 연속 실행해야 합니다. 기존 방식은 현재 동작이 끝날 때까지 대기 후 다음 명령을 전송해야 했습니다.
Goal Queueing은 동작 실행 중에도 새로운 Goal을 수락하여 내부 큐에 저장하고, 현재 동작 완료 즉시 다음 동작을 자동 시작합니다.
비동기 큐잉의 장점:
- 상위 제어기가 로봇 상태를 일일이 확인하지 않고 명령 선전송 가능
- 동작 간 전환 지연 최소화 → 멈춤 없는 연속 공정
- 네트워크 지연에 강건한 구조
핵심 메커니즘 3: Convergence Detection
모든 포인트 전송 완료 ≠ 물리적 동작 완료
로봇이 마지막 포인트에 실제로 도달했는지 확인해야 다음 궤적을 안전하게 시작할 수 있습니다.
Convergence 판정 알고리즘:
여기서:
- :
/joint_states에서 수신한 실제 관절 위치 - : 궤적의 마지막 포인트
- : 수렴 임계값 (e.g., 0.001 rad ≈ 0.057°)
bool check_convergence(const std::vector<double>& target_positions)
{
auto current_positions = get_current_joint_positions();
// 관절 수 불일치 체크
if (current_positions.size() != target_positions.size()) {
RCLCPP_ERROR(get_logger(), "Joint count mismatch: %zu vs %zu",
current_positions.size(), target_positions.size());
return false;
}
for (size_t i = 0; i < target_positions.size(); ++i) {
double error = std::abs(current_positions[i] - target_positions[i]);
if (error > convergence_threshold_) {
return false;
}
}
return true;
}
void wait_for_convergence(const std::vector<double>& target_positions,
std::chrono::milliseconds timeout)
{
auto start = std::chrono::steady_clock::now();
while (rclcpp::ok()) {
if (check_convergence(target_positions)) {
RCLCPP_INFO(get_logger(), "Convergence achieved");
return;
}
auto elapsed = std::chrono::steady_clock::now() - start;
if (elapsed > timeout) {
RCLCPP_WARN(get_logger(), "Convergence timeout");
return;
}
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
구현 상세
ROS 2 Action Server와 Threading Model
ROS 2의 Executor는 콜백 실행을 관리합니다. 기본 Single-Threaded Executor에서 handle_accepted 콜백 내 긴 루프는 다른 콜백을 블로킹합니다.
해결책: handle_accepted에서 작업 스레드를 생성하여 비동기 처리
class PointQueueProxy : public rclcpp::Node
{
public:
PointQueueProxy() : Node("point_queue_proxy")
{
// Action Server 생성
action_server_ = rclcpp_action::create_server<FollowJointTrajectory>(
this,
"follow_joint_trajectory",
std::bind(&PointQueueProxy::handle_goal, this, _1, _2),
std::bind(&PointQueueProxy::handle_cancel, this, _1),
std::bind(&PointQueueProxy::handle_accepted, this, _1)
);
// Service Client 생성
queue_point_client_ = create_client<QueueTrajPoint>("queue_traj_point");
// Joint States Subscriber
joint_states_sub_ = create_subscription<JointState>(
"joint_states", 10,
std::bind(&PointQueueProxy::joint_states_callback, this, _1)
);
}
private:
rclcpp_action::GoalResponse handle_goal(
const rclcpp_action::GoalUUID& uuid,
std::shared_ptr<const FollowJointTrajectory::Goal> goal)
{
RCLCPP_INFO(get_logger(),
"Received goal with %zu points",
goal->trajectory.points.size());
return rclcpp_action::GoalResponse::ACCEPT_AND_EXECUTE;
}
void handle_accepted(const std::shared_ptr<GoalHandleFJT> goal_handle)
{
std::lock_guard<std::mutex> lock(queue_mutex_);
if (is_executing_) {
// 실행 중이면 큐에 저장
goal_queue_.push_back(goal_handle);
RCLCPP_INFO(get_logger(), "Goal queued. Queue size: %zu",
goal_queue_.size());
} else {
// 유휴 상태면 즉시 실행
is_executing_ = true;
std::thread(&PointQueueProxy::execute_trajectory, this, goal_handle)
.detach();
}
}
void execute_trajectory(std::shared_ptr<GoalHandleFJT> goal_handle)
{
auto goal = goal_handle->get_goal();
auto result = std::make_shared<FollowJointTrajectory::Result>();
RCLCPP_INFO(get_logger(),
"Executing trajectory with %zu points",
goal->trajectory.points.size());
// 모든 포인트 스트리밍
for (size_t i = 0; i < goal->trajectory.points.size(); ++i) {
if (goal_handle->is_canceling()) {
goal_handle->canceled(result);
process_next_goal();
return;
}
int ret = queue_point_with_retry(goal->trajectory.points[i]);
if (ret != ResultCode::SUCCESS) {
result->error_code = FollowJointTrajectory::Result::INVALID_GOAL;
goal_handle->abort(result);
process_next_goal();
return;
}
// Feedback 발행 (선택적)
if (i % 100 == 0) {
auto feedback = std::make_shared<FollowJointTrajectory::Feedback>();
feedback->desired = goal->trajectory.points[i];
goal_handle->publish_feedback(feedback);
}
}
// Convergence 대기
auto last_point = goal->trajectory.points.back();
wait_for_convergence(last_point.positions,
std::chrono::seconds(30));
result->error_code = FollowJointTrajectory::Result::SUCCESSFUL;
goal_handle->succeed(result);
process_next_goal();
}
void process_next_goal()
{
std::lock_guard<std::mutex> lock(queue_mutex_);
if (!goal_queue_.empty()) {
auto next_goal = goal_queue_.front();
goal_queue_.pop_front();
std::thread(&PointQueueProxy::execute_trajectory, this, next_goal)
.detach();
} else {
is_executing_ = false;
}
}
// Member variables
rclcpp_action::Server<FollowJointTrajectory>::SharedPtr action_server_;
rclcpp::Client<QueueTrajPoint>::SharedPtr queue_point_client_;
rclcpp::Subscription<JointState>::SharedPtr joint_states_sub_;
std::mutex queue_mutex_;
std::deque<std::shared_ptr<GoalHandleFJT>> goal_queue_;
std::atomic<bool> is_executing_{false};
// Configuration
std::chrono::milliseconds busy_wait_time_{5};
int max_retries_{100};
double convergence_threshold_{0.001}; // rad
};
파라미터 튜닝 가이드
| 파라미터 | 낮은 값 | 높은 값 | 권장 |
|---|---|---|---|
busy_wait_time | 빠른 전송, BUSY 빈발 | 느린 전송, 안정적 | 4~8 ms |
max_retries | 빠른 실패, 불안정 | 느린 실패, 안정적 | 50~100 |
convergence_threshold | 정밀, 긴 대기 | 느슨, 빠른 전환 | 0.001 rad |
튜닝 원칙:
- busy_wait_time: MotoROS2의 내부 Motion API가 4ms 주기로 동작하므로 이를 기준으로 설정
- max_retries: 네트워크 지연, 복잡한 궤적을 고려하여 충분히 여유 있게 설정
- convergence_threshold: 후속 궤적의 시작점 허용 오차와 일치시켜 불연속 방지
실험 결과
테스트 환경
| 항목 | 사양 |
|---|---|
| 로봇 | Yaskawa GP12 (6-axis) |
| 컨트롤러 | YRC1000 |
| MotoROS2 버전 | 0.1.1 |
| ROS 2 배포판 | Humble |
| 네트워크 | 1 Gbps Ethernet (직결) |
정량적 성과
| 지표 | Before (기본 MotoROS2) | After (Proxy Server) |
|---|---|---|
| 최대 포인트 수/궤적 | 200 | 10,000+ |
| 궤적 연속성 | 분할 시 끊김 발생 | 완전 연속 |
| 포인트 유실률 | 가변적 (BUSY 미처리 시 발생) | 0% |
| 연속 공정 대기 시간 | ~500ms (Action 전환) | 10ms 미만 |
실제 적용 사례
정밀 용접 패턴
- 복잡한 Seam 추적: 3,200 포인트
- 기존: 16개 Action으로 분할 → 용접 품질 저하
- Proxy Server: 단일 Action으로 연속 실행 → 균일한 용접 비드
3D 프린팅 경로
- Layer당 평균 5,000+ 포인트
- 끊김 없는 압출로 적층 품질 향상
한계점 및 향후 과제
현재 한계
-
실시간 서보잉(Real-time Servoing) 미지원
- 현재 구조는 사전 계획된 궤적 실행에 최적화
- 센서 피드백 기반 실시간 경로 수정에는 추가 개발 필요
-
단일 로봇 제어
- 다중 로봇(Multi-robot) 동기화 미지원
- 향후 Goal 동기화 메커니즘 추가 계획
-
에러 복구
- 중간 실패 시 부분 실행된 궤적 롤백 메커니즘 미구현
향후 개선 방향
- MotoROS2 Point Streaming Interface (v0.0.15+) 통합
- 다중 로봇 동기화 지원
- Trajectory Blending으로 더 부드러운 전환
핵심 정리
-
MotoROS2의 200포인트 제한은 Micro-ROS의 메시지 크기 제약(~64KB)에서 기인합니다.
-
QueueTrajPoint서비스는 실제 큐가 없어BUSY응답 시 데이터 유실이 발생합니다. -
Point Queue Proxy Server는 두 문제를 동시에 해결합니다:
- Reliable Streaming: 흐름 제어로 포인트 유실 방지
- Goal Queueing: 연속 공정의 끊김 없는 실행
- Convergence Detection: 물리적 동작 완료 확인
-
핵심 기술: TCP 흐름 제어 원리를 로봇 모션 제어에 적용
정밀한 궤적 제어는 드라이버의 한계를 이해하고, 적절한 미들웨어 설계로 극복할 수 있습니다.