
YOLO 모델 최적화: Jetson Orin AGX에서 TensorRT와 DeepStream으로 2배 빠른 추론 달성
PyTorch 기반 YOLO 모델의 추론 시간을 15ms에서 7ms로 단축하고, FPS를 67에서 142로 끌어올린 방법. 재활용 플라스틱 자동 선별 시스템에서 TensorRT와 DeepStream을 활용한 최적화 과정을 공유합니다.
문제: 컨베이어 위 밀리초의 싸움
컨베이어 벨트 위를 0.5m/s로 지나가는 플라스틱을 분류해야 했습니다. PP(폴리프로필렌), PS(폴리스티렌), PE(폴리에틸렌) 세 종류. 탐지부터 델타 로봇이 집어 올리기까지 50ms 이내로 동작해야 했습니다.
PyTorch + OpenCV 조합으로 시작했습니다. 추론 시간 15ms, 67 FPS. 요구사항인 30 FPS는 충족했지만, 물체가 밀집되어 지나갈 때 탐지 누락이 발생했습니다. 더 빠른 추론이 필요했습니다.
| 항목 | 요구사항 | 초기 달성 |
|---|---|---|
| 목표 FPS | 30 FPS 이상 | 67 FPS |
| 최대 지연시간 | 50ms 이하 | 15ms |
| 탐지 정확도 | 99% 이상 | 99.2% |
| 컨베이어 속도 | 0.4~0.6m/s | - |
왜 Jetson Orin AGX인가?
엣지 AI의 필수 조건
클라우드 추론은 선택지가 아니었습니다. 네트워크 지연만으로 50ms를 초과할 수 있고, 네트워크 장애 시 전체 라인이 멈춥니다. 현장에서 직접 추론하는 엣지 AI가 필수였습니다.
Jetson Orin AGX를 선택한 이유:
| 항목 | Jetson Orin AGX 사양 |
|---|---|
| GPU | NVIDIA Ampere 아키텍처, 2048 CUDA 코어, 64 Tensor 코어 |
| AI 성능 | 최대 275 TOPS (INT8) |
| CPU | 12코어 Arm Cortex-A78AE |
| 메모리 | 64GB LPDDR5 (통합 메모리) |
| 전력 소비 | 15W ~ 60W (설정 가능) |
| 크기 | 소형 모듈 폼팩터 |
산업 현장 적합성
| 요구사항 | Jetson Orin AGX |
|---|---|
| 실시간 처리 | 275 TOPS AI 성능으로 고속 추론 |
| 컴팩트한 설치 | 소형 폼팩터로 현장 설치 용이 |
| 발열/전력 | 팬리스 또는 소형 방열판으로 동작 가능, 저전력 |
| 신뢰성 | 산업용 온도 범위 지원 (-25°C ~ 80°C) |
| 네트워크 독립 | 로컬 추론으로 네트워크 장애 영향 없음 |
통합 메모리 아키텍처의 강점
일반 데스크톱 GPU는 CPU 메모리와 GPU 메모리가 분리되어 있습니다. 데이터를 GPU에서 처리하려면 CPU→GPU 복사가 필요하고, 이 과정이 병목이 됩니다.
Jetson은 통합 메모리 아키텍처(Unified Memory)를 사용합니다. CPU와 GPU가 동일한 물리 메모리를 공유하므로, 데이터 복사 없이 바로 접근할 수 있습니다.
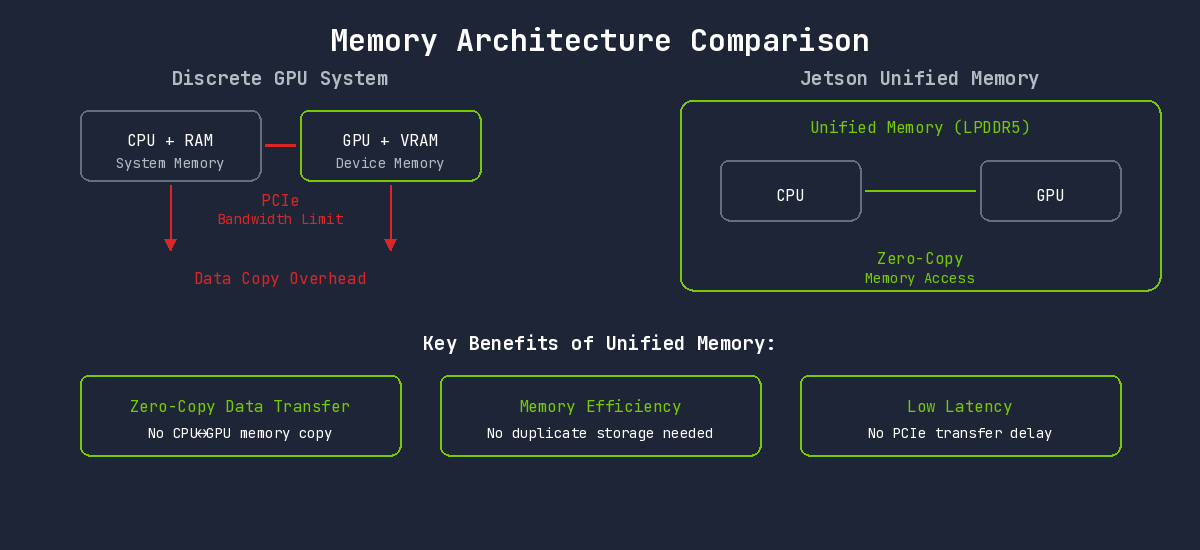
이 아키텍처 덕분에:
- Zero-Copy 데이터 전달: 카메라에서 읽은 영상을 복사 없이 GPU에서 바로 처리
- 메모리 효율성: 동일 데이터를 CPU/GPU가 중복 저장할 필요 없음
- 낮은 지연시간: PCIe 전송 지연 없음
TensorRT: 추론 전용 최적화 엔진
PyTorch의 한계
PyTorch로 학습한 모델을 그대로 추론에 사용하면 오버헤드가 존재합니다:
- 동적 계산 그래프 구성 오버헤드
- Python GIL(Global Interpreter Lock) 영향
- 동적 메모리 할당
TensorRT는 모델 구조가 고정되어 있다는 점을 활용합니다. 컴파일 타임에 모든 최적화를 수행하고, 런타임에는 순수하게 연산만 실행합니다.
핵심 최적화 기법
1. Layer Fusion (레이어 융합)
딥러닝 모델의 각 레이어는 별도의 CUDA 커널로 실행됩니다. 각 커널마다 GPU 메모리 읽기/쓰기가 발생하고, 커널 런칭 오버헤드가 있습니다.
TensorRT는 연속된 레이어들을 하나의 커널로 융합합니다:
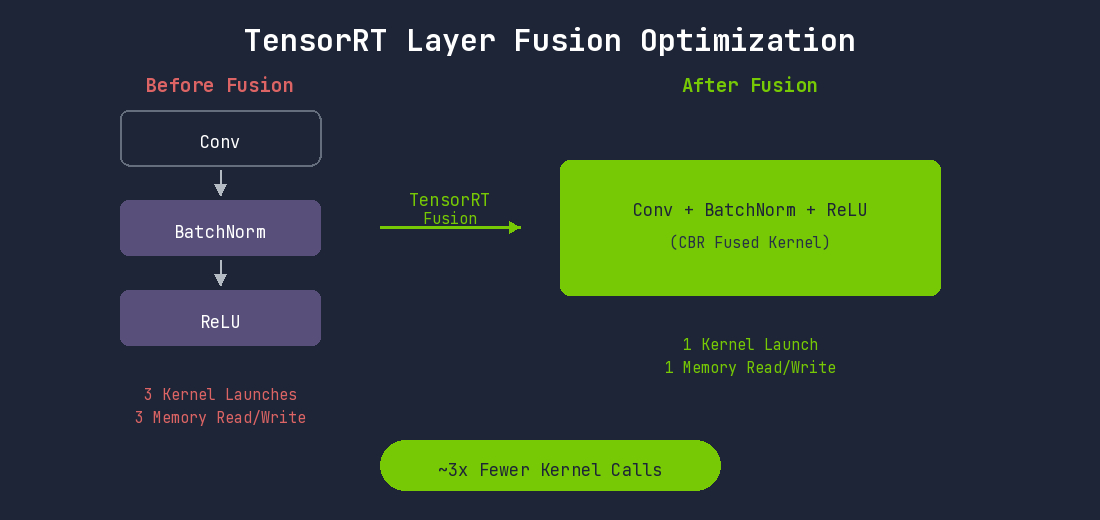
YOLO 모델에서 Convolution-BatchNorm-SiLU 패턴이 수십 번 반복됩니다. 이 모든 패턴이 융합되면서 커널 실행 횟수가 크게 줄어듭니다.
2. Precision Calibration (정밀도 최적화)
학습은 FP32로 진행되지만, 추론 시에는 더 낮은 정밀도로도 충분한 경우가 많습니다.
Jetson Orin의 Ampere GPU는 Tensor Core를 통해 FP16과 INT8 연산을 하드웨어 수준에서 가속합니다.
| Mode | 장점 | 단점 | 권장 상황 |
|---|---|---|---|
| FP32 | 정확도 손실 없음 | Tensor Core 미활용, 속도 느림 | 디버깅 또는 정확도 검증 |
| FP16 | Tensor Core 활용, 2배+ 빠름, 메모리 절반 | 극히 드물게 정확도 손실 | Jetson 기본 권장값 |
| INT8 | 최대 성능, Tensor Core 최적 활용 | Calibration 필수 | 속도 최우선 시 |
INT8 사용 시에는 Calibration 과정이 필요합니다. 대표적인 데이터셋을 모델에 통과시켜 각 레이어의 활성화 값 분포를 파악하고, 최적의 스케일링 팩터를 결정합니다.
3. Kernel Auto-Tuning (커널 자동 튜닝)
같은 연산이라도 GPU 아키텍처, 입력 크기, 배치 크기에 따라 최적의 CUDA 커널 구현이 다릅니다. TensorRT는 엔진 빌드 시점에 다양한 커널 구현을 실제로 실행해보고, 현재 환경에서 가장 빠른 구현을 선택합니다.
중요: TensorRT 엔진은 빌드된 환경에 종속적입니다. 반드시 Jetson Orin AGX에서 직접 엔진을 빌드해야 합니다.
4. Dynamic Tensor Memory (동적 텐서 메모리)
추론 과정에서 중간 텐서들은 이후 레이어에서 더 이상 사용되지 않으면 메모리를 해제해도 됩니다. TensorRT는 이러한 텐서들의 생명주기를 분석하여 메모리를 효율적으로 재사용합니다. Jetson의 제한된 메모리 환경에서 이 최적화는 특히 중요합니다.
TensorRT 변환 워크플로우

ONNX 파일은 플랫폼 독립적이므로 서버에서 내보낼 수 있지만, TensorRT 엔진 빌드는 반드시 타겟 디바이스(Jetson)에서 수행해야 합니다.
DeepStream: End-to-End 영상 처리 파이프라인
기존 방식의 병목
Python + OpenCV + PyTorch 파이프라인의 문제점과 DeepStream의 해결 방식을 비교하면:
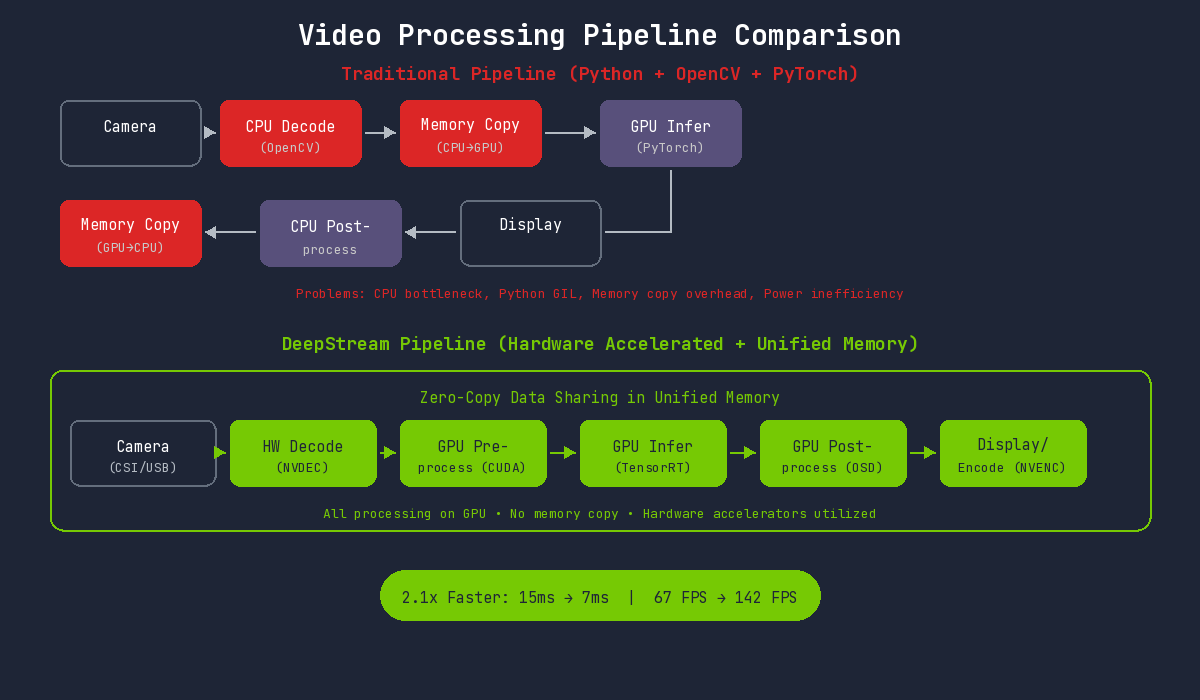
Jetson에서 기존 방식의 문제:
- CPU 디코딩 병목: ARM CPU는 데스크톱 대비 디코딩 성능이 제한적
- Python 오버헤드: GIL과 인터프리터 오버헤드
- 비효율적 메모리 사용: 통합 메모리 이점을 활용하지 못함
- 전력 낭비: CPU 집중 작업으로 전력 효율 저하
DeepStream의 해결 방식
DeepStream은 Jetson의 통합 메모리와 하드웨어 가속기를 최대한 활용합니다. 모든 처리가 GPU에서 이루어지고, 메모리 복사 없이 하드웨어 가속기들이 유기적으로 동작합니다.
Jetson 전용 하드웨어 가속기 활용
Jetson Orin AGX에는 GPU 외에도 여러 하드웨어 가속기가 내장되어 있습니다:
| 하드웨어 | 역할 | DeepStream 활용 |
|---|---|---|
| NVDEC | 비디오 디코딩 | H.264/H.265 하드웨어 디코딩 |
| NVENC | 비디오 인코딩 | 결과 영상 저장/스트리밍 |
| VIC | Vision Image Compositor | 이미지 리사이즈, 컬러 변환 |
| DLA | Deep Learning Accelerator | 추가 AI 추론 (GPU 오프로드) |
DeepStream은 이 모든 하드웨어를 자동으로 활용하여 GPU 부하를 분산시킵니다.
다중 스트림 처리
단일 DeepStream 파이프라인에서 여러 카메라 스트림을 동시에 처리할 수 있습니다. Jetson의 전력 효율성과 결합하면, 저전력으로 다중 카메라 시스템을 구축할 수 있습니다.
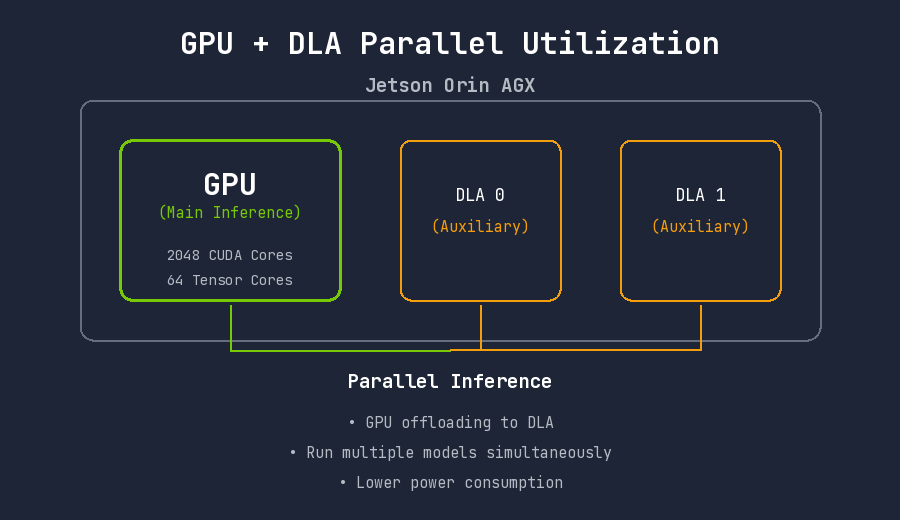
DLA (Deep Learning Accelerator) 활용
Jetson Orin AGX에는 2개의 DLA가 내장되어 있습니다. DLA는 GPU와 독립적으로 동작하는 AI 가속기로, 특정 레이어를 DLA에서 실행하면 GPU 자원을 다른 작업에 활용할 수 있습니다.
DLA 지원 여부 확인:
/usr/src/tensorrt/bin/trtexec \
--onnx=yolo.onnx \
--useDLACore=0 \
--allowGPUFallback \
--fp16
DeepStream 파이프라인 구조
GStreamer 기반의 플러그인 시스템으로 구성됩니다:
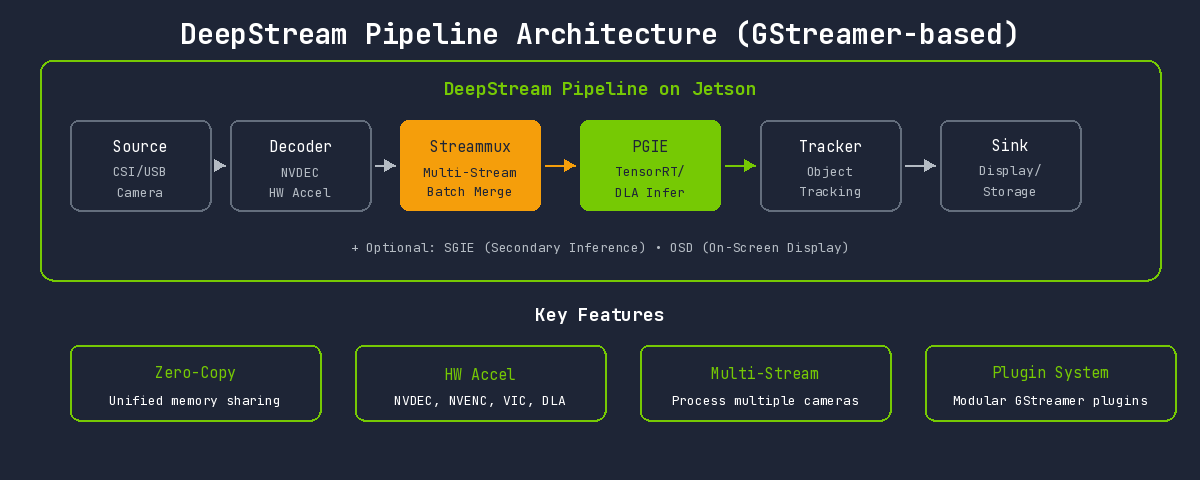
| Element | 역할 | Jetson 특화 사항 |
|---|---|---|
| Source | 입력 소스 | CSI 카메라 직접 연결 지원 (nvarguscamerasrc) |
| Decoder | 영상 디코딩 | NVDEC 하드웨어 가속 (nvv4l2decoder) |
| Streammux | 스트림 멀티플렉서 | 통합 메모리에서 효율적 배치 구성 |
| PGIE | Primary GPU Inference | TensorRT + DLA 선택 가능 |
| SGIE | Secondary Inference | 2차 분류에 DLA 활용 가능 |
| Tracker | 객체 추적 | NvDCF, IOU 등 GPU 가속 트래커 |
| OSD | On-Screen Display | GPU 기반 오버레이 렌더링 |
| Sink | 출력 | nvoverlaysink (Jetson 디스플레이 최적화) |
적용 사례: 플라스틱 분류 시스템
기술적 도전 과제
재활용 시설에서 컨베이어 벨트 위를 지나가는 플라스틱을 실시간으로 분류하여 자동 선별 시스템에 신호를 전달해야 했습니다. 분류 결과에 따라 델타 로봇이 플라스틱을 해당 수거함으로 분리합니다.
- 낮은 지연시간: 컨베이어 속도가 빠르기 때문에 탐지부터 로봇 동작까지의 지연시간이 짧아야 합니다
- 높은 처리량: 물체가 밀집되어 지나갈 때도 모든 객체를 탐지해야 합니다
- 조명 변화 대응: 산업 현장의 조명 조건은 일정하지 않습니다
- 유사한 외관: PP, PS, PE는 육안으로도 구분이 어려운 경우가 많습니다
- 엣지 자원 제한: 제한된 연산 자원 내에서 목표 성능 달성 필요
성능 비교 결과
실험 환경
| 항목 | 사양 |
|---|---|
| 디바이스 | NVIDIA Jetson Orin AGX 64GB |
| JetPack | 6.0 |
| TensorRT | 8.6.2 |
| DeepStream | 6.4 |
| 모델 | YOLOv8s |
| 입력 해상도 | 640x480 |
| 전력 모드 | MAXN (60W) |
추론 속도 비교
| 환경 | Inference Time | FPS | 속도 향상 |
|---|---|---|---|
| PyTorch (Python, FP32) | 15ms | 67 fps | 기준 |
| TensorRT (Python, FP16) | 7ms | 142 fps | 2.1배 |
정확도 비교
정밀도 변환에 따른 정확도 변화:
| 환경 | mAP@0.5 | mAP@0.5:0.95 | 정확도 변화 |
|---|---|---|---|
| PyTorch (FP32) | 99.2% | 87.5% | 기준 |
| TensorRT (FP16) | 99.1% | 87.3% | -0.1% |
| TensorRT (INT8) | 98.9% | 86.1% | -0.3% |
FP16 변환 시 정확도 손실은 0.1%로, 실질적으로 무시할 수 있는 수준입니다.
클래스별 탐지 성능
| 클래스 | Precision | Recall | AP@0.5 |
|---|---|---|---|
| PP (폴리프로필렌) | 99.3% | 98.9% | 99.1% |
| PS (폴리스티렌) | 98.8% | 99.2% | 99.0% |
| PE (폴리에틸렌) | 99.1% | 99.4% | 99.3% |
테스트 조건
- 테스트 기간: 2주 연속 운영
- 학습 이미지 수: 약 800,000개
- 컨베이어 조건: 약 0.5m/s
최적화 과정에서의 인사이트
TensorRT 변환 시 주의점
1. 반드시 Jetson에서 엔진 빌드
TensorRT 엔진은 하드웨어 종속적입니다. 서버에서 빌드한 엔진은 Jetson에서 동작하지 않습니다.
2. Dynamic Shape vs Static Shape
Jetson의 제한된 메모리 환경에서는 Static Shape이 더 효율적입니다. 입력 크기가 고정되어 메모리 할당이 최적화됩니다.
3. DLA 활용 검토
일부 레이어를 DLA에서 실행하면 GPU 자원을 절약할 수 있습니다. 단, 모든 레이어가 DLA를 지원하지는 않으므로 호환성 확인이 필요합니다.
DeepStream 적용 시 고려사항
1. Jetson 전력 모드 설정
Jetson Orin AGX는 여러 전력 모드를 지원합니다:
# 최대 성능 모드
sudo nvpmodel -m 0 # MAXN 모드
# 전력 모드 확인
nvpmodel -q
2. Tracker 선택
| Tracker | 특징 | Jetson 적합성 |
|---|---|---|
| IOU Tracker | 간단하고 빠름 | 매우 적합 (낮은 오버헤드) |
| NvDCF | GPU 가속, 정확도 높음 | 적합 (추가 GPU 자원 사용) |
| DeepSORT | Re-ID 기반 | 주의 (추가 모델 필요, 자원 소모) |
컨베이어 환경에서는 객체 이동 방향이 일정하므로 IOU Tracker로도 충분했습니다.
결론
정량적 성과
| 지표 | PyTorch 기준 | 최적화 후 | 개선율 |
|---|---|---|---|
| 추론 속도 | 15ms | 7ms | 46% 단축 |
| FPS | 67 fps | 142 fps | 215% 향상 |
| 정확도 (mAP@0.5) | 99.2% | 99.1% | -0.1% (무시 가능) |
정성적 성과
- 엣지 독립 운영: 네트워크 의존 없이 현장에서 완전한 자율 운영
- 안정성 향상: Python 환경의 메모리 누수, GIL 문제에서 해방
- 전력 효율: 저전력 운용
- 유지보수 용이: 설정 파일 기반 파이프라인 구성으로 모델 교체 간편
핵심 정리
-
Jetson은 서버가 아니다: 서버에서 사용하던 코드와 모델을 그대로 가져오면 성능이 나오지 않습니다. Jetson 환경에 맞는 최적화가 필수입니다.
-
통합 메모리를 활용하라: Jetson의 가장 큰 장점인 통합 메모리와 DeepStream 같은 Zero-Copy 파이프라인은 궁합이 좋습니다.
-
하드웨어 가속기를 모두 활용하라: GPU만이 아니라 NVDEC, NVENC, DLA까지 활용하면 End-to-End 프로세스에서 좋은 성능을 발휘합니다.
-
전력 모드를 적절히 설정하라: MAXN 모드가 항상 최선은 아닙니다. 발열과 전력 제한을 고려해야 합니다. 다만 우리 프로젝트에서는 한여름 더운 폐기물 처리장에서도 MAXN 모드로 장시간 구동해도 문제가 없었습니다.
Jetson Orin AGX는 엣지에서 실시간 AI 추론이 필요한 산업 현장에 적합한 플랫폼이었습니다. TensorRT와 DeepStream을 통해 제한된 자원에서도 서버급 성능에 근접한 결과를 얻을 수 있었습니다. 특히 컨베이어 플라스틱 분류처럼 지연시간과 처리량이 모두 중요한 환경에서 그 가치가 더욱 빛났습니다.