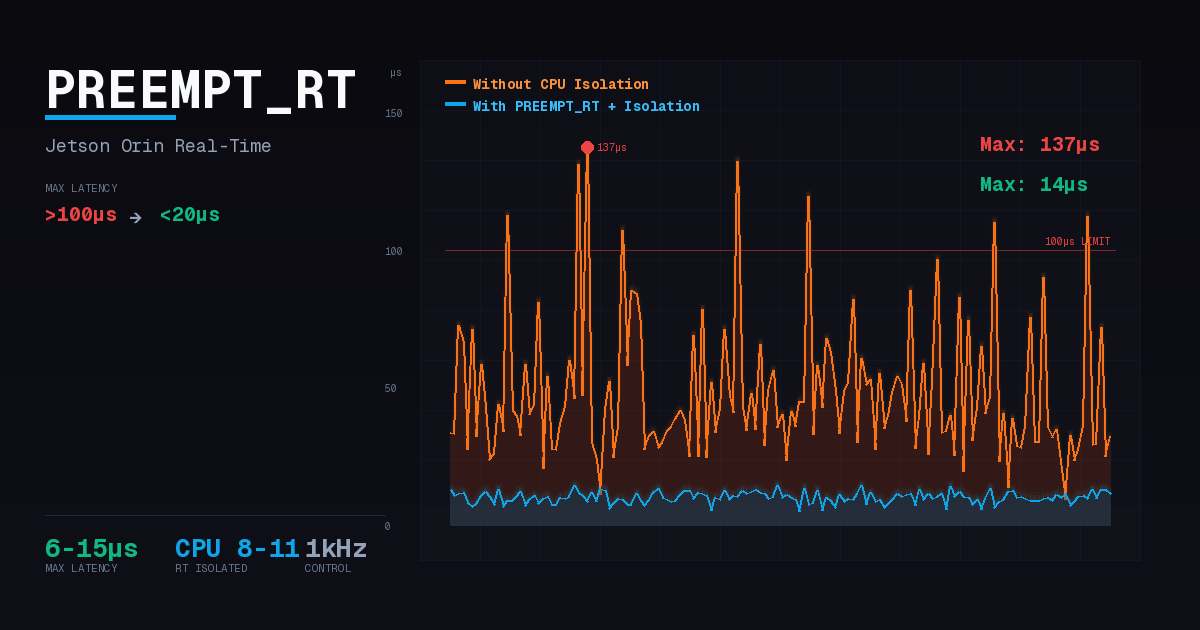
PREEMPT_RT만으로 충분할까? Jetson Orin 실시간 성능 검증
로봇 제어 시스템을 Jetson에 올리려는 엔지니어라면 한 번쯤 이런 고민을 합니다.
"PREEMPT_RT 커널만 설치하면 1kHz 제어가 가능할까? 아니면 커스텀 커널 빌드까지 해야 할까?"
이 글에서는 Jetson Orin AGX에서 NVIDIA 공식 RT 패키지 + CPU 격리 설정만으로 1kHz EtherCAT 제어에 필요한 레이턴시 요구사항을 충족하는지 실측 데이터로 검증합니다.
결론부터 말하면: PREEMPT_RT만으로는 부족합니다. CPU 격리 없이는 GPU, Storage, EtherCAT 부하에서 100µs를 초과하는 비정상 jitter 스파이크가 빈번하게 발생했습니다. PREEMPT_RT + CPU 격리를 함께 적용해야 모든 부하 조건에서 Max latency 20µs 이하를 달성할 수 있었습니다.
1kHz 제어와 레이턴시 요구사항
왜 100µs인가?
1kHz 제어 루프는 1ms(1000µs) 주기로 동작합니다. 매 주기마다 다음 작업이 순차적으로 실행되어야 합니다:
- Wakeup - RT 태스크가 스케줄러에 의해 깨어남
- Read - EtherCAT 프레임 수신, 센서 데이터 읽기
- Compute - 제어 알고리즘 연산 (PID, 역기구학 등)
- Write - 모터 명령 전송
이 모든 작업이 1ms 내에 완료되어야 다음 주기를 놓치지 않습니다. 일반적으로 wakeup latency가 주기의 10% 이하여야 나머지 작업에 충분한 시간이 확보됩니다. 따라서 1kHz 제어의 wakeup latency 기준은 100µs입니다.
EtherCAT 통신이 취약한 이유
EtherCAT 마스터는 주기적으로 프레임을 송수신합니다. 이 과정에서 발생하는 문제:
- 인터럽트 간섭: NVMe, GPU, 네트워크 등의 인터럽트가 RT 태스크를 선점하면 프레임 송신 시점이 지연됩니다
- 스케줄링 지연: 커널 스레드(ksoftirqd, kworker 등)가 RT 태스크보다 먼저 실행되면 wakeup이 늦어집니다
- DC 동기화 문제: EtherCAT Distributed Clocks는 마스터 jitter를 어느 정도 보상하지만, 지연이 심해지면 다음 주기 프레임 전송 Deadline을 놓쳐 제어 루프 데이터 갱신이 누락됩니다. DC는 1µs 미만의 슬레이브 간 동기화를 제공하지만, 마스터 측 타이밍은 별도로 관리해야 합니다
결과적으로 모터 토크 출력 지연, 위치 추종 오차 증가, 심한 경우 제어 루프 발산으로 이어질 수 있습니다.
참고 연구
ROS2 환경에서 EtherCAT 제어 성능을 측정한 연구(ROS2 Performance Study, 2023)에서는 평균 2µs, 최대 82µs의 레이턴시를 보고했습니다. 이는 1kHz 제어 기준(100µs)을 충족하는 수치입니다.
테스트 목표와 환경
테스트 목표
앞서 설명한 것처럼 EtherCAT 마스터는 인터럽트와 스케줄링에 취약합니다. PREEMPT_RT 커널만으로는 이러한 간섭을 완전히 차단할 수 없습니다. CPU 격리를 통해 RT 태스크 전용 코어를 확보하면, 대부분의 시스템 활동(GPU 렌더링, NVMe I/O, 일반 커널 스레드 등)이 해당 코어에서 실행되지 않습니다. 단, IPI(프로세서 간 인터럽트), 로컬 타이머, per-CPU 커널 스레드 등 일부 예외는 남습니다.
핵심 질문: NVIDIA OTA RT 패키지 + CPU 격리만으로 1kHz 제어 루프에 충분한가?
이 테스트는 CPU 8-11을 격리한 상태에서 다양한 시스템 부하가 발생해도 wakeup latency가 100µs를 초과하는 스파이크 없이 안정적으로 유지되는지 검증합니다.
테스트 환경
| 항목 | 사양 |
|---|---|
| 하드웨어 | Jetson Orin AGX 64GB |
| 커널 | NVIDIA RT 패키지 (OTA) |
| 전원 모드 | MAXN + jetson_clocks |
| 테스트 시간 | 10분 (600,000 samples) |
| 측정 도구 | cyclictest -p 80 -i 1000 -l 600000 -m -a 8-11 |
| RT 스로틀링 | 비활성화 (sched_rt_runtime_us=-1) |
| 성공 기준 | 모든 테스트 Max latency < 100µs |
RT 커널의 효과
먼저 RT 커널 자체의 효과를 확인합니다. 복합 부하(CPU + I/O + Memory) 조건에서:
| 커널 | Max Latency | 비고 |
|---|---|---|
| non-RT (stock) | 318µs | 100µs 기준 초과 |
| RT (PREEMPT_RT) | 56µs | 82% 개선 |
PREEMPT_RT만으로 318µs → 56µs로 82% 개선됩니다. 단순 stress-ng 복합 부하에서는 100µs 기준을 충족하지만, 이것으로 "실시간 제어가 가능하다"고 결론 내리면 안 됩니다.
실제 운영환경에서는 GPU 렌더링, NVMe I/O, EtherCAT 통신 등 다양한 부하가 발생합니다. 이러한 실제 부하 조건에서 테스트하면 PREEMPT_RT만으로는 비정상 jitter 스파이크가 빈번하게 발생합니다.
PREEMPT_RT의 동작 원리
PREEMPT_RT 패치는 표준 Linux 커널을 완전 선점형(fully preemptible) 커널로 변환합니다. 핵심 변경 사항:
Threaded IRQ (인터럽트 스레드화)
표준 커널에서 인터럽트 핸들러는 인터럽트 컨텍스트에서 실행되어 스케줄러가 개입할 수 없습니다. PREEMPT_RT는 대부분의 인터럽트 핸들러를 커널 스레드(irq/N-name)로 변환하여 스케줄링 대상으로 만듭니다.
IRQ 스레드는 기본적으로 SCHED_FIFO 우선순위 50으로 실행됩니다. 따라서 우선순위가 더 높은 RT 태스크(예: 80)는 IRQ 스레드보다 먼저 스케줄링될 수 있습니다. 단, top-half(hardirq)는 여전히 인터럽트 컨텍스트에서 실행되며, IRQF_NO_THREAD로 마킹된 인터럽트(타이머, IPI 등)는 스레드화되지 않습니다.
Priority Inheritance (우선순위 상속)
우선순위 역전(priority inversion) 은 실시간 시스템의 고전적 문제입니다:
- 저우선순위 태스크(L)가 락을 획득
- 고우선순위 RT 태스크(H)가 같은 락을 요청 → 대기
- 중간 우선순위 태스크(M)가 L을 선점 → H가 M보다 늦게 실행됨
PREEMPT_RT의 RT-Mutex는 우선순위 상속을 구현합니다. L이 락을 보유하고 H가 대기하면, L의 우선순위가 일시적으로 H와 같아져서 M이 L을 선점할 수 없습니다. L이 락을 해제하면 원래 우선순위로 복귀합니다.
이 메커니즘은 1997년 Mars Pathfinder 미션에서 우선순위 역전으로 인한 시스템 리셋 문제 이후 실시간 시스템의 필수 요소가 되었습니다.
Spinlock → RT-Mutex 변환
표준 커널의 spin_lock은 busy-waiting으로 구현됩니다. CPU를 점유한 채 락 해제를 기다리므로 다른 태스크가 실행될 수 없습니다.
PREEMPT_RT는 대부분의 spin_lock을 sleepable RT-mutex로 변환합니다:
| 구분 | 표준 커널 (spinlock) | PREEMPT_RT (RT-mutex) |
|---|---|---|
| 대기 방식 | Busy-waiting (CPU 점유) | Sleep (CPU 양보) |
| 선점 가능 | ❌ | ✅ |
| 우선순위 상속 | ❌ | ✅ |
단, raw_spin_lock은 변환되지 않고 원래의 spinlock으로 유지됩니다. 인터럽트 비활성화가 필요한 최소한의 구간(하드웨어 레지스터 접근 등)에서 사용됩니다.
이로써 RT-mutex로 보호되는 커널 critical section에서 선점이 가능해져, 고우선순위 RT 태스크가 저우선순위 커널 작업에 의해 블로킹되는 시간이 크게 줄어듭니다.
PREEMPT_RT의 한계
PREEMPT_RT는 강력하지만 모든 jitter 원인을 해결하지는 못합니다:
| jitter 원인 | PREEMPT_RT 해결 | 추가 조치 필요 |
|---|---|---|
| 인터럽트 핸들러 지연 | ✅ Threaded IRQ | - |
| 우선순위 역전 | ✅ Priority Inheritance | - |
| 커널 critical section | ✅ RT-Mutex | - |
| 인터럽트 발생 위치 | ❌ | irqaffinity 필요 |
| 캐시 오염 | ❌ | isolcpus 필요 |
| 커널 스레드 경쟁 | ❌ | kthread_cpus 필요 |
| 타이머 틱 | ❌ | nohz_full 필요 (OTA 미포함) |
PREEMPT_RT는 "RT 태스크가 실행될 수 있는 상황이면 즉시 실행된다" 를 보장하지만, "RT 태스크가 실행되는 CPU에 방해 요소가 접근하지 못하게 한다" 는 보장하지 않습니다. 이것이 CPU 격리가 필요한 근본적인 이유입니다.
왜 CPU 격리가 필요한가?
RT 커널을 설치해도 CPU 격리 없이는 특정 부하 조건에서 레이턴시가 급증합니다. 이 현상을 이해하려면 운영체제의 인터럽트 처리, 캐시 아키텍처, 스케줄링 메커니즘을 살펴봐야 합니다.
Jitter의 근본 원인
실시간 제어에서 "jitter"는 주기적인 태스크의 실행 시간 변동을 의미합니다. 평균 레이턴시가 낮더라도 간헐적으로 비정상적인 스파이크가 발생하면 제대로 된 실시간 제어라고 할 수 없습니다.
PREEMPT_RT 커널에서도 jitter 스파이크가 발생하는 핵심 원인은 다음과 같습니다:
1. 인터럽트 간섭 (Interrupt Interference)
Linux 커널은 인터럽트 처리를 두 단계로 나눕니다:
- Top-half (hardirq): IRQ 발생 즉시 실행. 인터럽트 비활성화 상태에서 하드웨어 ACK 등 최소한의 처리만 수행
- Bottom-half: 실제 데이터 처리. PREEMPT_RT에서는 커널 스레드(
irq/N-name)로 실행되어 선점 가능
문제는 top-half는 여전히 인터럽트 컨텍스트에서 실행된다는 점입니다. NVMe I/O, GPU, 네트워크 등의 인터럽트가 발생하면, 아무리 짧아도 RT 태스크는 top-half가 끝날 때까지 대기해야 합니다.
PREEMPT_RT의 threaded IRQ 덕분에 bottom-half는 스케줄링 대상이 되지만, 인터럽트가 어느 CPU에서 처리될지는 IRQ affinity 설정에 따릅니다. 격리 없이는 RT 태스크가 실행 중인 코어에서도 top-half가 실행될 수 있습니다.
2. 캐시 오염 (Cache Pollution)
현대 CPU는 메모리 접근 속도를 높이기 위해 다단계 캐시(L1/L2/L3)를 사용합니다. RT 태스크가 선점되면:
- 다른 프로세스/커널 스레드가 CPU에서 실행됨
- 해당 프로세스의 데이터가 캐시에 로드됨 → RT 태스크의 캐시 라인이 축출(eviction)
- RT 태스크가 재개될 때 캐시 미스(cache miss) 발생
- 메인 메모리 접근 필요 → 수십~수백 사이클 지연
이 현상은 TLB(Translation Lookaside Buffer)에서도 동일하게 발생합니다. TLB 미스는 페이지 테이블 워크(page table walk)를 유발하여 추가 지연을 발생시킵니다.
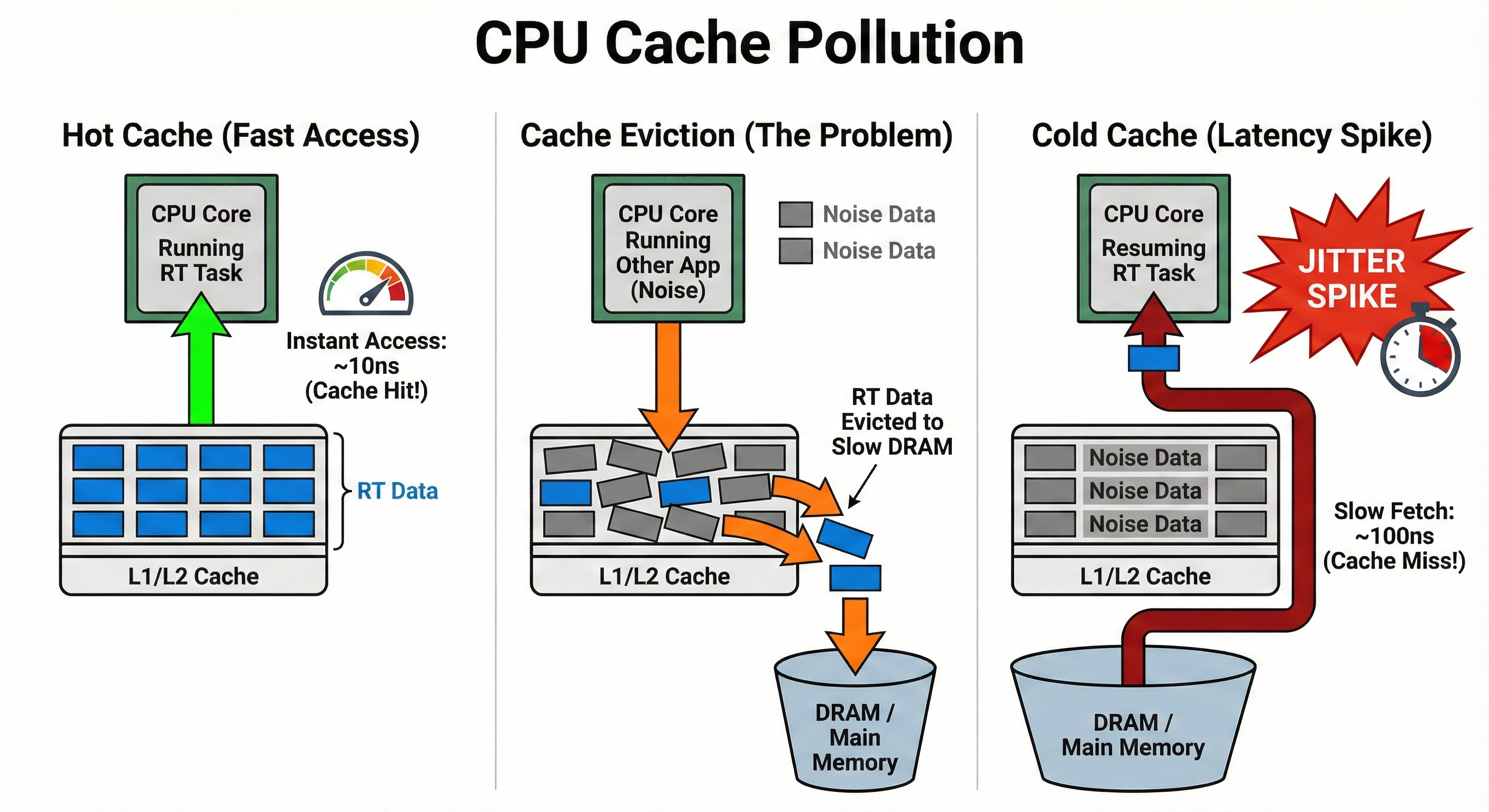
Hot Cache(~10ns) → Cache Eviction → Cold Cache(~100ns): 캐시 미스로 인한 10배 지연이 jitter 스파이크의 원인
3. 커널 스레드 경쟁 (Kernel Thread Contention)
Linux 커널은 다양한 백그라운드 작업을 커널 스레드로 처리합니다:
| 커널 스레드 | 역할 | RT 태스크에 미치는 영향 |
|---|---|---|
ksoftirqd | 소프트 인터럽트 처리 (네트워크, 타이머) | softirq 지연 시 배치 처리로 지연 유발 |
kworker | 비동기 커널 작업 큐 처리 | 예측 불가능한 시점에 실행 |
rcu_preempt | RCU 콜백 처리 | 모든 CPU에서 주기적으로 실행 |
migration | CPU 간 태스크 이동 | 이동된 태스크가 cold cache에서 시작 |
이 스레드들은 기본적으로 모든 CPU에서 실행될 수 있으며, RT 태스크와 경쟁합니다.
4. 타이머 틱 오버헤드 (Timer Tick Overhead)
기본 Linux 커널은 모든 CPU에 주기적인 타이머 인터럽트(tick)를 발생시킵니다. 각 틱마다:
- 인터럽트 핸들러 실행
- 스케줄러 호출 (런큐 확인)
- 시간 관련 통계 업데이트
- RCU 콜백 확인
이 오버헤드는 보통 수 마이크로초지만, 다른 요인과 결합되면 스파이크로 이어집니다. nohz_full 옵션은 격리된 CPU에서 이 틱을 제거하지만, NVIDIA OTA RT 패키지에는 포함되어 있지 않습니다.
CPU 격리의 동작 원리
CPU 격리는 커널의 여러 서브시스템에 동시에 작용합니다. 각 파라미터가 커널 레벨에서 어떻게 동작하는지 살펴봅니다.
isolcpus: 스케줄러 도메인에서 제외
isolcpus=domain,8-11은 커널 스케줄러의 로드 밸런싱 대상에서 CPU 8-11을 제외합니다:
# /sys/devices/system/cpu/cpu8/domain* 확인
# 격리된 CPU는 자신만의 단일 CPU 도메인을 가짐
커널 스케줄러는 주기적으로 CPU 간 태스크를 재분배(load balancing)합니다. 격리된 CPU는 이 과정에서 제외되어:
- 일반 프로세스가 자동 배치되지 않음
- RT 태스크의 L1/L2 캐시와 TLB가 오염되지 않음 (LLC/L3는 공유되어 영향 가능)
taskset또는sched_setaffinity()로 명시적으로 지정한 태스크만 실행됨
isolcpus는 부팅 후 변경할 수 없다는 제약이 있어, 런타임 유연성이 필요한 환경에서는 cgroup/cpuset이 권장됩니다. 하지만 실시간/임베디드 시스템에서는 isolcpus가 더 확실한 격리를 제공합니다. NVIDIA 공식 RT 커널 문서에서도 isolcpus=managed_irq,domain을 권장합니다.
irqaffinity: 인터럽트 라우팅 제어
irqaffinity=0-7은 커널 부팅 시 모든 IRQ의 기본 affinity를 CPU 0-7로 설정합니다:
# 부팅 후 확인
cat /proc/irq/*/smp_affinity_list
# 대부분의 디바이스 IRQ가 0-7로 설정됨 (per-CPU/managed IRQ는 예외)
이 설정은 /proc/irq/<irq>/smp_affinity의 기본값을 변경합니다. 단, userspace 드라이버나 irqbalance가 런타임에 변경할 수 있으므로 프로덕션 환경에서는 irqbalance를 비활성화하거나 설정을 잠그는 것이 권장됩니다.
kthread_cpus: 커널 스레드 격리
kthread_cpus=0-7은 커널 스레드 생성 시 기본 CPU affinity를 제한합니다:
# 부팅 후 확인
ps -eo pid,comm,psr | grep -E 'ksoftirqd|kworker|rcu'
# 대부분의 커널 스레드가 CPU 0-7에서 실행됨
단, 모든 커널 스레드가 이 설정을 따르지는 않습니다. 일부 per-CPU 커널 스레드(예: migration/N, cpuhp/N)는 특정 CPU에 바인딩되어 있어 이동할 수 없습니다. 이런 스레드는 격리된 CPU에서도 실행되지만, 실행 빈도가 낮아 실제 영향은 미미합니다.
세 파라미터의 시너지
| 계층 | 파라미터 | 격리 대상 |
|---|---|---|
| 스케줄러 | isolcpus=domain | 일반 프로세스 |
| 인터럽트 | irqaffinity | 하드웨어 인터럽트 |
| 커널 | kthread_cpus | 커널 백그라운드 스레드 |
세 파라미터를 함께 사용해야 완전한 격리가 달성됩니다. isolcpus만 설정하면 프로세스는 격리되지만 인터럽트와 커널 스레드는 여전히 RT 코어를 침범합니다.
평균 vs 최악 레이턴시
실시간 시스템에서 중요한 것은 평균(average)이 아닌 최악(worst-case) 레이턴시입니다.
| 메트릭 | 의미 | 1kHz 제어에서의 영향 |
|---|---|---|
| 평균 레이턴시 | 대부분의 경우 성능 | 일반적인 제어 품질 |
| 최악 레이턴시 | 가장 나쁜 경우 성능 | 한 번이라도 초과하면 제어 실패 |
로봇 제어에서 jitter 스파이크는 모터 토크 출력 지연, 센서 피드백 누락, 제어 루프 불안정으로 이어집니다.
격리 미적용 상태에서 10분간(600,000 샘플) 테스트한 결과:
| 부하 | Avg Latency | Max Latency | 판정 |
|---|---|---|---|
| Idle | 2.4µs | 22µs | PASS |
GPU (glmark2) | 3.6µs | 159µs | FAIL |
| EtherCAT (1kHz DC) | 3.8µs | 113µs | FAIL |
Storage (fio) | 5.3µs | 145µs | FAIL |
System (stress-ng) | 6.1µs | 47µs | PASS |
평균 레이턴시는 모두 10µs 이하로 양호하지만, Max latency가 100µs를 초과하는 스파이크가 GPU, EtherCAT, Storage 부하에서 발생했습니다. 이런 스파이크가 반복되면 제어 품질 저하로 이어지며, 정밀 제어가 필요한 응용에서는 허용되지 않습니다.
CPU 격리 설정
CPU 8-11을 RT 전용으로 격리하기 위해 다음 부트 파라미터를 적용했습니다:
| 파라미터 | 역할 |
|---|---|
isolcpus=managed_irq,domain,8-11 | 스케줄러 격리 + 관리형 IRQ 격리 |
irqaffinity=0-7 | 일반 IRQ를 CPU 0-7로 제한 |
kthread_cpus=0-7 | 커널 스레드를 CPU 0-7로 제한 |
isolcpus만으로는 불완전합니다. managed_irq 플래그는 커널이 자동 관리하는 IRQ(MSI-X, NVMe 등)만 격리하기 때문에, 일반 IRQ와 커널 스레드의 완전한 격리를 위해 irqaffinity와 kthread_cpus를 함께 사용해야 합니다.
애플리케이션 레벨 최적화
커널 설정만으로는 충분하지 않습니다. RT 태스크 자체도 올바르게 구성해야 실시간 성능을 얻을 수 있습니다.
RT 스케줄링 정책 설정
Linux는 여러 스케줄링 정책을 제공합니다:
| 정책 | 우선순위 | 특성 |
|---|---|---|
SCHED_OTHER | (없음) | 기본 정책, RT 태스크에 항상 선점됨 |
SCHED_FIFO | 1-99 | RT 정책, 높은 우선순위가 낮은 우선순위를 선점 |
SCHED_RR | 1-99 | RT 정책, FIFO + 동일 우선순위 간 타임슬라이스 |
1kHz 제어 태스크에는 SCHED_FIFO가 적합합니다. 타임슬라이스 없이, 태스크가 스스로 양보(sched_yield)하거나 더 높은 우선순위에 선점될 때까지 실행되어 동작이 결정론적입니다.
RT 태스크 설정의 세 가지 요소
RT 태스크가 결정론적으로 동작하려면 세 가지를 설정해야 합니다:
| 설정 | API / 명령어 | 목적 |
|---|---|---|
| 메모리 락 | mlockall() | 페이지 폴트로 인한 ms 단위 지연 방지 |
| CPU Affinity | sched_setaffinity() 또는 taskset | 격리된 CPU에서만 실행 |
| RT 스케줄링 | sched_setscheduler() | SCHED_FIFO 정책 적용 |
설정 순서가 중요합니다:
mlockall()— 페이지 폴트를 RT 스케줄링 적용 전에 처리- CPU affinity — 격리된 CPU에 바인딩
sched_setscheduler()— 마지막에 RT 정책 적용
mlockall()을 먼저 호출하는 이유: 메모리 페이지 로드 시 page fault가 발생할 수 있는데, RT 스케줄링이 적용된 후에는 이 지연이 제어 루프에 직접 영향을 미칩니다.
- 스택 확장 대비:
mlockall()은 현재 할당된 스택을 잠그지만, 스택이 확장되면 새 페이지에서 page fault가 발생할 수 있습니다. RT 루프 진입 전에 충분한 크기의 로컬 배열을 선언하여 스택을 미리 확장(prefaulting)하세요. - 메모리 용량 확인: 모든 메모리를 물리 RAM에 고정하므로, 시스템 메모리가 부족하면 OOM killer가 다른 프로세스를 종료할 수 있습니다.
CPU 격리 적용 후 결과
동일한 부하 조건에서 CPU 격리 적용 후 재측정:
| 부하 | 격리 전 (Max) | 격리 후 (Max) | 개선율 |
|---|---|---|---|
| Idle | 22µs | 8µs | 64% |
| GPU | 159µs ❌ | 15µs ✅ | 91% |
| EtherCAT | 113µs ❌ | 6µs ✅ | 95% |
| Storage | 145µs ❌ | 7µs ✅ | 95% |
| System | 47µs | 15µs | 68% |
격리 전 FAIL이었던 3개 테스트(GPU, EtherCAT, Storage)가 모두 PASS로 전환되었습니다. 테스트 구간(10분/600k 샘플)에서 100µs 초과 스파이크가 관측되지 않았으며, 모든 테스트에서 Max latency 20µs 이하를 달성했습니다. 1kHz 제어 기준(100µs)에 충분한 여유가 있는 수치입니다.
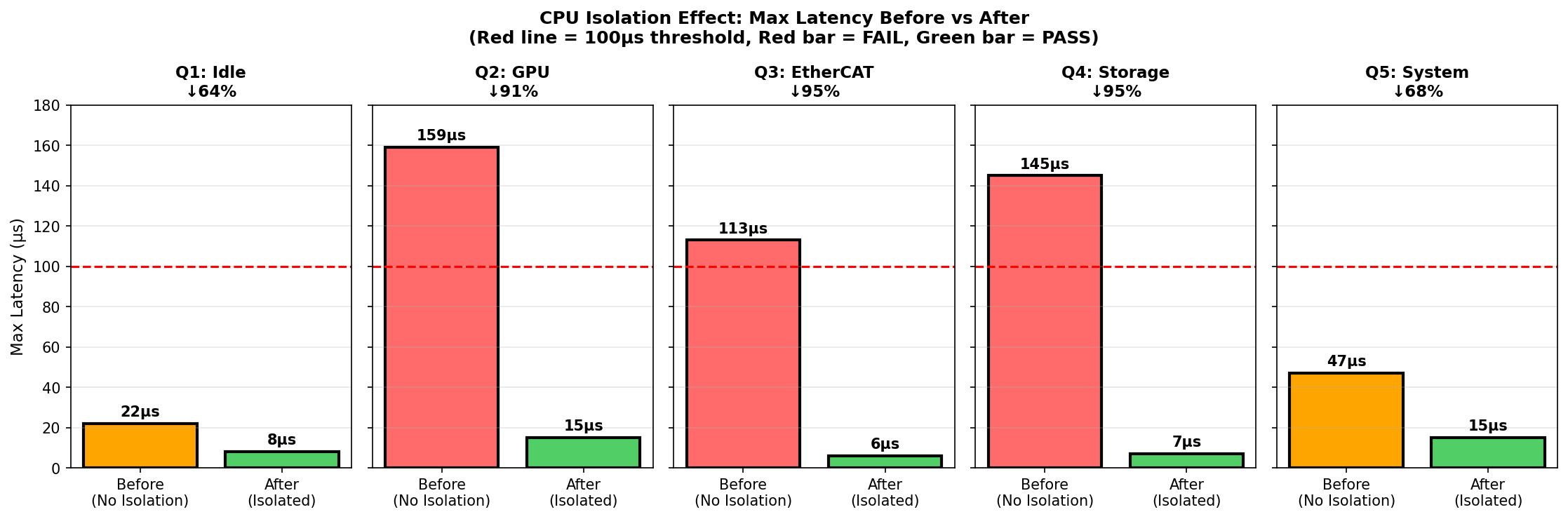
빨간 막대: 100µs 초과 (FAIL), 초록 막대: 100µs 이하 (PASS), 점선: 100µs 기준
시계열 분포 비교
10분간 측정한 레이턴시 분포를 비교하면 격리 효과가 더 명확합니다:
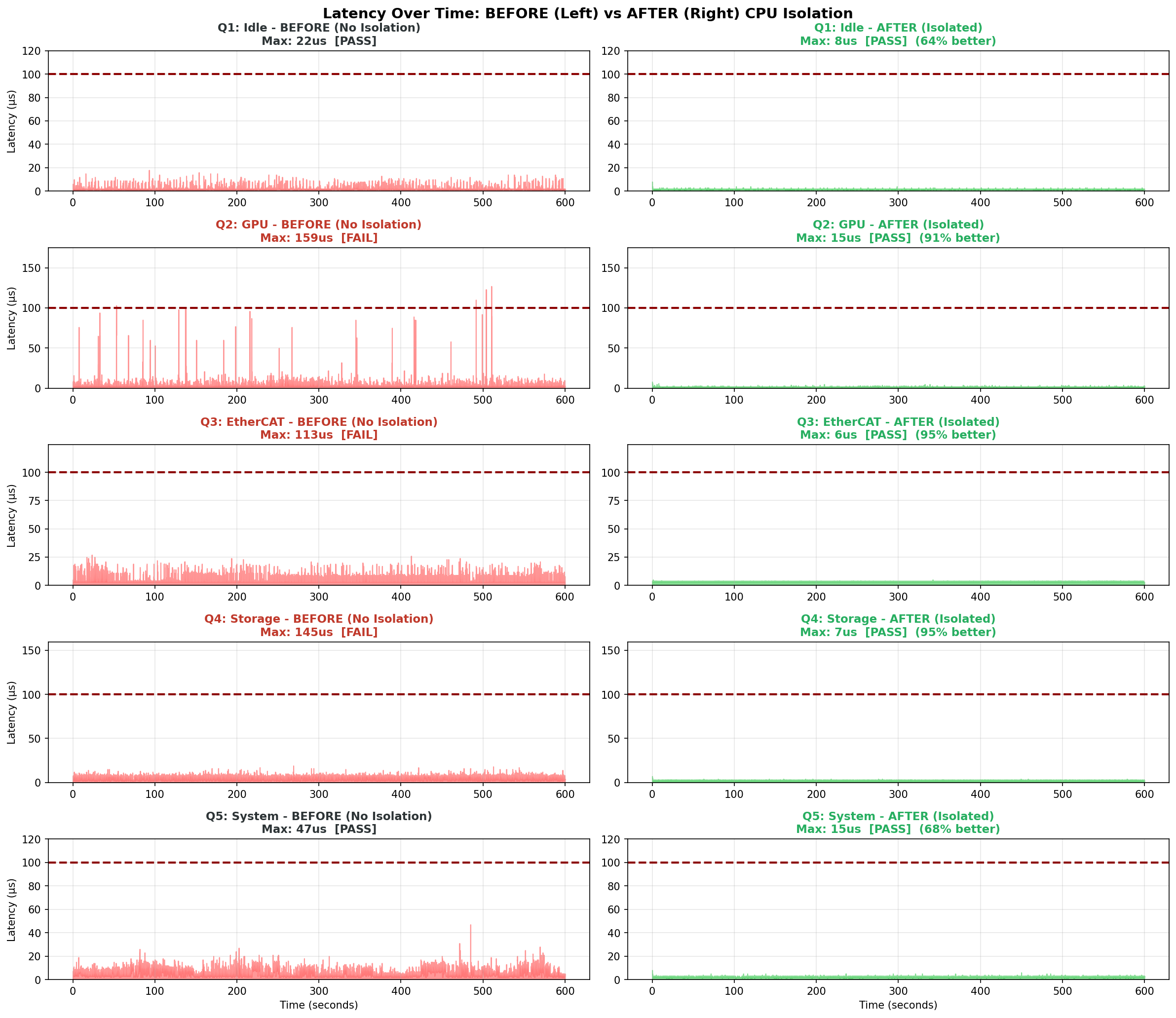
격리 미적용(왼쪽)에서는 간헐적으로 100µs를 초과하는 스파이크가 발생합니다. 평균 레이턴시는 양호해 보이지만, 10분 테스트에서도 이러한 스파이크가 여러 차례 관측되었습니다.
격리 적용(오른쪽)에서는 측정된 모든 샘플이 15µs 이하로 안정적으로 유지되었습니다. 이것이 "실시간 제어"의 본질입니다 - 평균이 아닌 최악의 경우도 관리하는 것.
커스텀 커널 탐색 과정
앞서 보여드린 Q-tests 결과는 NVIDIA OTA RT 패키지를 사용한 것입니다. 하지만 우리는 커스텀 커널 빌드까지 탐색했습니다. 산업 표준에서 권장하는 nohz_full, rcu_nocbs 옵션이 정말 필요한지 검증하기 위해서입니다.
왜 커스텀 빌드를 고려했는가?
Linux Kernel 공식 문서와 Intel ECI SDK, Red Hat RT 등에서는 실시간 시스템에 다음 옵션을 권장합니다:
CONFIG_NO_HZ_FULL: 격리된 CPU에서 타이머 틱 제거CONFIG_RCU_NOCB_CPU: RCU 콜백을 다른 CPU로 오프로드
NVIDIA OTA RT 패키지에는 이 옵션들이 포함되어 있지 않습니다. 따라서 부트 파라미터로 nohz_full=8-11, rcu_nocbs=8-11을 설정해도 무시됩니다.
커스텀 커널 빌드 테스트 (M-tests)
커스텀 커널(CONFIG_NO_HZ_FULL=y, CONFIG_RCU_NOCB_CPU=y)을 빌드하여 Idle 및 복합 부하(L2: CPU + I/O + Memory) 조건에서 테스트했습니다:
| 조건 | 커널 | 격리 | 부하 | Max Latency | 상태 |
|---|---|---|---|---|---|
| M1 | non-RT | ❌ | Idle | 53µs | PASS |
| M2 | non-RT | ❌ | L2 | 318µs | FAIL |
| M3 | RT | ❌ | Idle | 23µs | PASS |
| M4 | RT | ❌ | L2 | 56µs | PASS |
| M5 | RT | ✅ | Idle | 26µs | PASS |
| M6 | RT | ✅ | L2 | 24µs | PASS |
M-tests 격리 부트 파라미터:
isolcpus=managed_irq,domain,8-11 nohz_full=8-11 rcu_nocbs=8-11 rcu_nocb_poll irqaffinity=0-7 kthread_cpus=0-7
단계별 개선 효과
| 단계 | 변화 | 개선율 |
|---|---|---|
| non-RT → RT (부하) | 318µs → 56µs | 82% ↓ |
| RT → RT+격리 (부하) | 56µs → 24µs | 57% ↓ |
| 전체 (M2 → M6) | 318µs → 24µs | 92% ↓ |
M-tests의 의미
M-tests와 Q-tests는 직접 비교할 수 없습니다:
- M-tests: 탐색적 테스트, stress-ng L2 부하만 사용, 1분
- Q-tests: 프로덕션 검증, GPU/EtherCAT/Storage 개별 부하, 10분(600,000 samples)
따라서 "M6(24µs) vs Q-tests(6-15µs)"로 "OTA가 더 좋다"고 단정할 수 없습니다.
M-tests가 보여주는 것:
- PREEMPT_RT의 효과: non-RT(318µs) → RT(56µs)로 82% 개선
- CPU 격리의 추가 효과: RT(56µs) → RT+격리(24µs)로 57% 추가 개선
- 커스텀 커널(NO_HZ_FULL)로 24µs 달성: 100µs 기준을 충분히 충족
Q-tests가 보여주는 것:
- OTA 패키지 + CPU 격리로 6-15µs 달성: 마찬가지로 100µs 기준 충족
- 다양한 실제 부하(GPU, Storage, EtherCAT)에서 검증됨
결론: 두 접근법 모두 1kHz 제어 요구사항(100µs)을 충족합니다. 다만 OTA 패키지는 설치가 간편하고, 커스텀 빌드는 복잡합니다. 동일 조건에서의 성능 차이를 검증하려면 추가 실험이 필요합니다.
커스텀 커널 빌드가 필요한 경우
JetPack 6.2 (L4T 36.x) 기준 OTA RT 패키지에는 다음 옵션이 포함되지 않습니다:
CONFIG_NO_HZ_FULL(Full dynticks)CONFIG_RCU_NOCB_CPU(RCU 콜백 오프로딩)
이 옵션들은 Linux Kernel 공식 문서에서 다음 경우에 권장합니다:
"Unless you are running realtime applications or certain types of HPC workloads, you will normally NOT want this option"
커스텀 빌드가 필요한 경우:
- PREEMPT_RT의 최악 레이턴시(~100µs)로도 부족한 경우
- 고속 금융 거래(HFT), 반도체 장비 제어 등 극한의 레이턴시 요구
커스텀 커널 빌드를 선택하면 다음 사항을 고려해야 합니다:
- 빌드 시간: 60-90분 소요 (OTA는 5-10분)
- NVMe rootfs 부팅 주의: NVMe 드라이버가 모듈(=m)이고 initrd에 포함되지 않으면 부팅 실패. Built-in(=y)이 가장 안전
- initrd 동기화 필수: 커널 빌드 후
/boot/initrd수동 업데이트 필요. 가장 흔한 부팅 실패 원인
대부분의 로봇 제어 애플리케이션에는 OTA 패키지로 충분합니다.
Q-tests에서 OTA 패키지 + CPU 격리만으로 6-15µs의 Max latency를 달성했고, M-tests에서 커스텀 커널로 24µs를 달성했습니다. 두 테스트의 조건이 달라 직접 비교는 어렵지만, 둘 다 100µs 기준을 충분히 충족합니다.
현재(2025년 12월) JetPack 7은 Jetson Thor 전용으로 출시되었으며, Orin 시리즈는 아직 공식 지원되지 않습니다. Orin용 JetPack 6이 현재 production 버전입니다. 다만 JetPack 7 공식 문서에서는 CONFIG_NO_HZ_FULL과 CONFIG_RCU_NOCB_CPU 관련 설정이 언급되어 있어, Orin용 JetPack 7이 출시되면 OTA RT 패키지에 해당 옵션이 포함될 가능성이 높습니다.
커스텀 빌드의 Trade-off
커스텀 빌드를 고려한다면 다음 trade-off를 인지해야 합니다:
| 측면 | 격리된 CPU | 전체 시스템 |
|---|---|---|
| 레이턴시 | 개선 | - |
| Housekeeping CPU 부하 | - | 증가 |
| Syscall 오버헤드 | 증가 | 증가 |
| Throughput | - | 감소 |
SUSE Labs의 분석:
"The jitter-free power you gain on your set of isolated CPUs comes at the expense of more work for the other CPUs"
핵심 정리
"PREEMPT_RT만으로 충분할까?"에 대한 답:
아니오. PREEMPT_RT만으로는 GPU, Storage, EtherCAT 부하에서 100µs를 초과하는 jitter 스파이크가 발생합니다. CPU 격리는 선택이 아닌 필수입니다.
1kHz EtherCAT 제어를 위한 필수 구성:
- NVIDIA 공식 RT 패키지 (OTA)
- CPU 격리:
isolcpus+irqaffinity+kthread_cpus(필수)
PREEMPT_RT + CPU 격리 적용 결과:
- 모든 부하 조건에서 Max latency 6-15µs 달성 (기준 100µs 대비 충분한 여유)
- GPU, Storage, EtherCAT 부하에서 91-95% jitter 개선
대부분의 로봇 제어 애플리케이션에서 커스텀 커널 빌드는 불필요합니다. 단, PREEMPT_RT만 설치하고 CPU 격리 없이 운영하면 실제 부하 조건에서 비정상 jitter가 발생할 수 있습니다.
참고 자료
공식 문서
- NVIDIA Real-Time Kernel Guide (L4T 36.x)
- Ubuntu - Real-time kernel tuning
- Linux Kernel - NO_HZ Documentation
CPU 격리 심화
Jetson 커널 빌드
- NVIDIA Kernel Customization (L4T 36.x)
- Jetson Orin Boot Flow - 부팅 아키텍처 이해
- UEFI Adaptation - extlinux.conf 설정