강화학습 기반 하위 모터 제어: PID/ADRC를 넘어서
"LLM으로 로봇 제어기 만들면 되는 거 아닌가요?"
최근 Claude Code, Cursor 같은 AI 코드 생성 도구의 발전으로 이런 질문을 자주 받습니다. 결론부터 말하면, LLM이 다룰 수 있는 영역과 다룰 수 없는 영역은 명확히 구분됩니다. 이 글에서는 LLM이 절대 대체할 수 없는 하위 제어 영역에서 WIM이 강화학습(RL)을 어떻게 적용하고 있는지 설명합니다.
결론 먼저
| 구분 | LLM / 코드 생성 도구 | WIM RL Motor Controller |
|---|---|---|
| 제어 주기 | 500~2,000ms | 1ms (1kHz) |
| 출력 | 텍스트 / 코드 | 모터 토크/속도/위치 명령 |
| 새 로봇 대응 | 코드 재작성 | 정책 재학습 (자동) |
| 적응 방식 | 프롬프트 수정 | Sim-to-Real 학습 |
| 안전 장치 | 없음 | PID/ADRC fallback + Safety Layer |
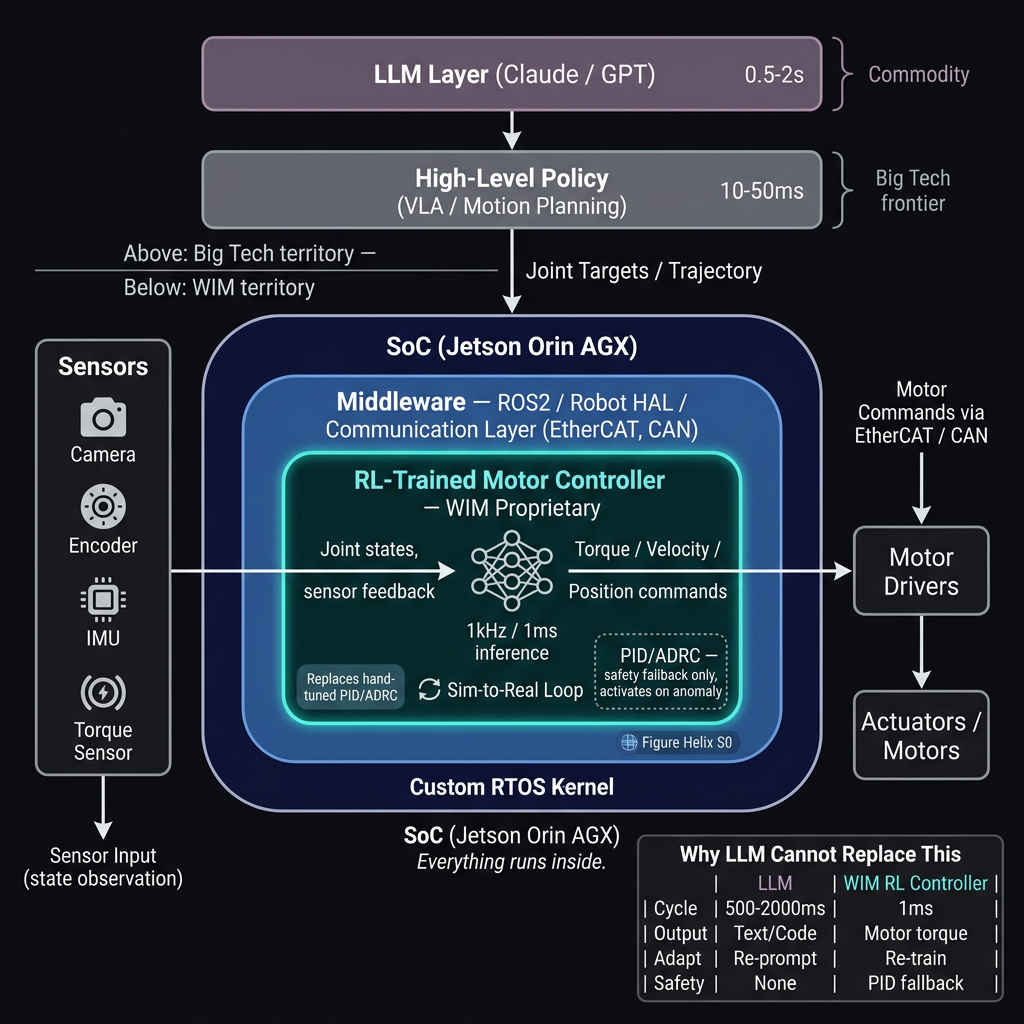
핵심: LLM은 500ms 단위로 텍스트를 생성합니다. 모터 제어는 1ms 단위로 토크를 출력해야 합니다. 1,000배 차이나는 시간 영역을 LLM이 대체할 수 없습니다.
로봇 제어의 계층 구조
로봇 제어는 단일 레이어가 아닙니다. 시간 스케일에 따라 명확한 계층이 존재합니다.
상위 두 계층(자연어 인터페이스, 상위 제어 정책)은 빅테크가 이미 활발히 개발하고 있습니다. Google의 Gemini Robotics, NVIDIA의 Isaac ROS, MoveIt2 같은 프레임워크가 이 영역을 다룹니다.
WIM이 집중하는 영역은 그 아래 — 1kHz로 모터를 직접 제어하는 하위 계층입니다.
기존 방식의 한계: PID/ADRC 수동 튜닝
산업용 로봇의 모터 제어는 전통적으로 PID 또는 ADRC(Active Disturbance Rejection Control) 제어기를 사용합니다.
여기서 , , 는 각각 비례·적분·미분 게인입니다. 문제는 이 게인 값을 로봇마다, 관절마다, 부하 조건마다 수동으로 튜닝해야 한다는 점입니다.
| 문제 | 설명 |
|---|---|
| 수동 튜닝 비용 | 로봇 1대당 엔지니어가 수일~수주 소요 |
| 비선형 동역학 | 마찰, 백래시, 중력 등을 선형 제어기가 완벽히 보상 불가 |
| 다기종 대응 | 로봇 기종이 바뀌면 처음부터 재튜닝 |
| 환경 변화 | 부하, 온도, 마모에 따라 성능 저하 |
실제로 저희가 이전에 수행한 가속도 피드포워드 최적화 작업에서도, 제어기 파라미터 하나를 개선하기 위해 6가지 방법을 비교 실험해야 했습니다. 이런 수동 과정을 자동화하는 것이 RL 도입의 핵심 동기입니다.
WIM의 접근: RL로 모터를 직접 제어
WIM은 PID/ADRC를 RL 기반 신경망으로 대체합니다. 시뮬레이션에서 학습한 정책이 실제 로봇에서 모터 토크를 직접 출력합니다.
Sim-to-Real 학습 파이프라인
핵심은 시뮬레이션 학습과 실제 로봇 검증을 동시에 진행한다는 점입니다. Sim-to-Real Gap을 지속적으로 측정하고, 실제 로봇의 피드백으로 시뮬레이터를 보정합니다.
PID/ADRC는 안전 Fallback으로 유지
RL 정책이 주 제어기이지만, PID/ADRC를 완전히 제거하지는 않습니다. 이상 상황(anomaly) 감지 시 즉시 클래식 제어기로 전환하는 safety fallback 구조를 유지합니다.
이 구조가 중요한 이유는 산업용 로봇의 안전 규격(ISO 10218) 대응 때문입니다. 신경망 제어기만으로는 인증이 어려울 수 있지만, 검증된 클래식 제어기가 fallback으로 존재하면 안전성 입증이 수월해집니다.
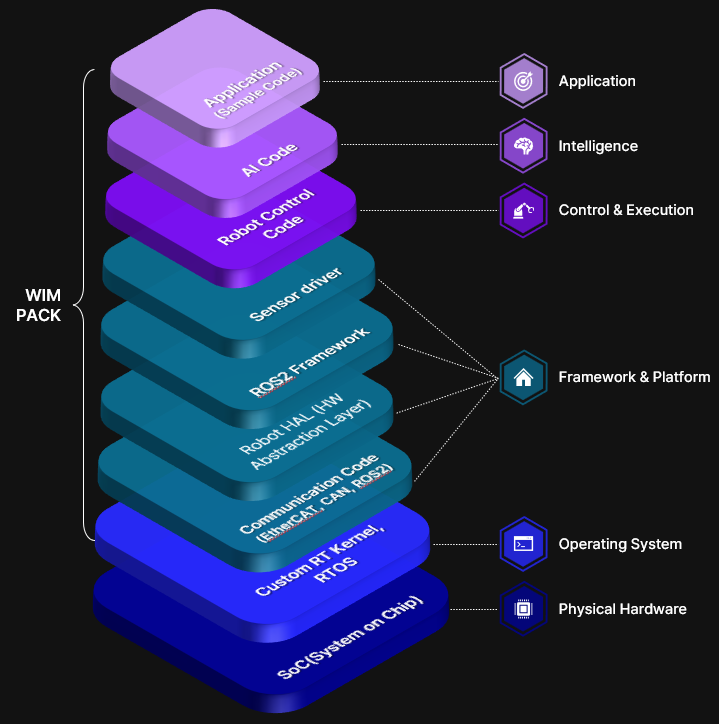
WIMPACK 소프트웨어 스택
RL 제어기는 단독으로 동작하지 않습니다. 실시간 통신, 하드웨어 추상화, 안전 레이어를 포함한 풀스택 소프트웨어 플랫폼 위에서 실행됩니다.
| 계층 | 구성 요소 | 역할 |
|---|---|---|
| Application | Sample Code, SDK | 사용자 애플리케이션 |
| Intelligence | AI Code | LLM 연동, 자연어 명령 처리 |
| Control & Execution | Robot Control Code | RL Motor Controller + PID Fallback |
| Framework & Platform | ROS2, Robot HAL, Communication (EtherCAT/CAN), Sensor Driver | 미들웨어 및 하드웨어 추상화 |
| Operating System | Custom RT Kernel, RTOS | 실시간 보장 |
| Physical Hardware | SoC (Jetson Orin AGX) | 연산 플랫폼 |
SoC(Jetson Orin AGX) 위에서 RTOS가 실시간을 보장하고, ROS2/HAL이 하드웨어를 추상화하며, 그 위에서 RL 제어기가 1kHz로 추론을 수행합니다. 모든 것이 하나의 임베디드 디바이스 안에서 동작합니다.
왜 LLM/코드 생성 도구로 대체할 수 없는가
마지막으로 이 질문에 정면으로 답하겠습니다.
1. 시간 영역의 차이
LLM은 토큰 단위로 텍스트를 생성합니다. 가장 빠른 LLM도 첫 응답까지 수백 밀리초가 걸립니다. 모터 제어는 1ms마다 새로운 토크 명령을 계산해야 합니다. 이 간극은 아키텍처의 근본적 한계이며, 모델 크기를 줄인다고 해결되지 않습니다.
2. 출력의 본질이 다르다
LLM의 출력은 코드(텍스트)입니다. RL 모터 컨트롤러의 출력은 시뮬레이션에서 수십만 에피소드를 거쳐 학습된 신경망 가중치입니다. "코드를 잘 짜면 되는 것"이 아니라, 물리 환경과의 상호작용을 통해 획득되는 지식입니다.
3. 다기종 대응의 확장성
코드 생성 도구로 제어기를 만들면 로봇이 바뀔 때마다 코드를 재작성해야 합니다. RL 기반 접근은 시뮬레이터에서 새 로봇 모델을 로드하고 재학습하면 됩니다. 로봇 기종이 늘어날수록 이 차이는 기하급수적으로 벌어집니다.
핵심 정리
- 상위 제어(자연어 → 명령, 작업 계획)는 빅테크의 영역이며, LLM과 VLA가 빠르게 발전 중
- 하위 모터 제어(1kHz 실시간 토크 출력)는 LLM으로 대체 불가능한 영역
- WIM은 이 하위 제어에서 RL로 PID/ADRC를 대체하되, 안전을 위해 클래식 제어기를 fallback으로 유지
- Sim-to-Real 파이프라인으로 시뮬레이션 학습과 실제 로봇 검증을 병행
- 로봇 기종이 바뀌어도 정책 재학습으로 자동 대응 — 수동 튜닝이 필요 없는 플랫폼