RL-Based Low-Level Motor Control: Beyond PID/ADRC
"Can't you just build a robot controller with an LLM?"
With the recent advances in AI code generation tools like Claude Code and Cursor, we get this question a lot. The short answer is: the domains LLMs can and cannot handle are clearly distinct. This article explains how WIM applies reinforcement learning (RL) in the low-level control domain that LLMs can never replace.
Bottom Line Up Front
| Category | LLM / Code Generation Tools | WIM RL Motor Controller |
|---|---|---|
| Control Cycle | 500--2,000ms | 1ms (1kHz) |
| Output | Text / Code | Motor torque/velocity/position commands |
| New Robot Adaptation | Rewrite code | Re-train policy (automated) |
| Adaptation Method | Modify prompts | Sim-to-Real training |
| Safety Mechanism | None | PID/ADRC fallback + Safety Layer |
The key point: LLMs generate text at 500ms intervals. Motor control must output torque at 1ms intervals. LLMs cannot replace a time domain that differs by a factor of 1,000.
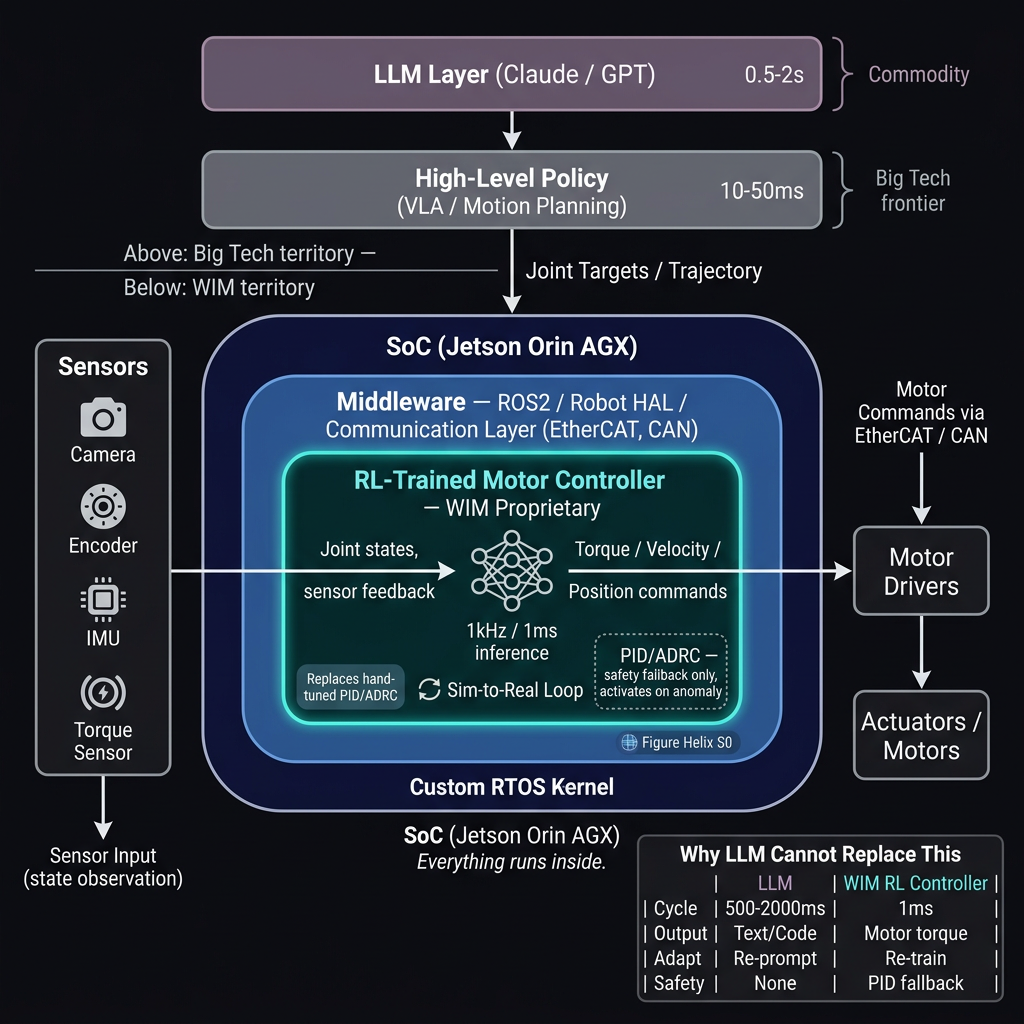
The Hierarchical Structure of Robot Control
Robot control is not a single layer. There is a clear hierarchy based on time scale.
The top two layers (natural language interface, high-level control policy) are already being actively developed by big tech. Frameworks like Google's Gemini Robotics, NVIDIA's Isaac ROS, and MoveIt2 address this domain.
WIM focuses on what lies beneath -- the low-level layer that directly controls motors at 1kHz.
Limitations of Traditional Approaches: Manual PID/ADRC Tuning
Motor control in industrial robots has traditionally relied on PID or ADRC (Active Disturbance Rejection Control) controllers.
Here, , , and are the proportional, integral, and derivative gains, respectively. The problem is that these gain values must be manually tuned for each robot, each joint, and each load condition.
| Problem | Description |
|---|---|
| Manual Tuning Cost | Engineers spend days to weeks per robot |
| Nonlinear Dynamics | Linear controllers cannot fully compensate for friction, backlash, gravity, etc. |
| Multi-Model Support | Tuning must restart from scratch when switching robot models |
| Environmental Changes | Performance degrades with changes in load, temperature, and wear |
In our previous work on acceleration feedforward optimization, we had to compare six different methods just to improve a single controller parameter. Automating this manual process is the core motivation for adopting RL.
WIM's Approach: Direct Motor Control with RL
WIM replaces PID/ADRC with an RL-based neural network. A policy trained in simulation directly outputs motor torque on real robots.
Sim-to-Real Training Pipeline
The key is that simulation training and real robot validation proceed simultaneously. The Sim-to-Real gap is continuously measured, and the simulator is calibrated using feedback from the real robot.
PID/ADRC Retained as a Safety Fallback
While the RL policy serves as the primary controller, PID/ADRC is not entirely removed. A safety fallback structure is maintained that immediately switches to the classical controller upon anomaly detection.
This structure is important for compliance with industrial robot safety standards (ISO 10218). While certification may be difficult with a neural network controller alone, having a proven classical controller as a fallback makes it significantly easier to demonstrate safety.
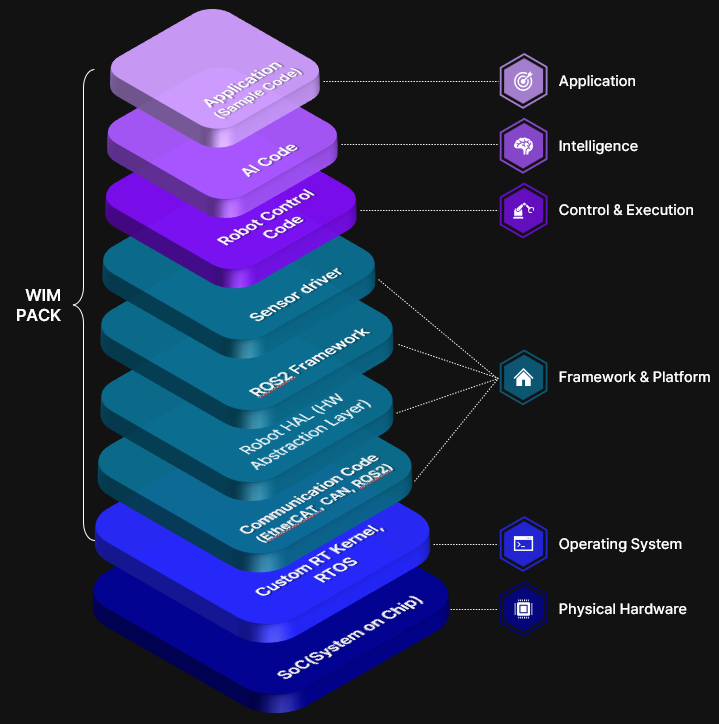
WIMPACK Software Stack
The RL controller does not operate in isolation. It runs on a full-stack software platform that includes real-time communication, hardware abstraction, and safety layers.
| Layer | Components | Role |
|---|---|---|
| Application | Sample Code, SDK | User applications |
| Intelligence | AI Code | LLM integration, natural language command processing |
| Control & Execution | Robot Control Code | RL Motor Controller + PID Fallback |
| Framework & Platform | ROS2, Robot HAL, Communication (EtherCAT/CAN), Sensor Driver | Middleware and hardware abstraction |
| Operating System | Custom RT Kernel, RTOS | Real-time guarantees |
| Physical Hardware | SoC (Jetson Orin AGX) | Compute platform |
On top of the SoC (Jetson Orin AGX), the RTOS guarantees real-time performance, ROS2/HAL abstracts the hardware, and the RL controller performs inference at 1kHz. Everything runs within a single embedded device.
Why LLMs and Code Generation Tools Cannot Replace This
Let us address this question head-on.
1. The Time Domain Gap
LLMs generate text token by token. Even the fastest LLMs take hundreds of milliseconds to produce their first response. Motor control must compute a new torque command every 1ms. This gap is a fundamental architectural limitation that cannot be solved by reducing model size.
2. The Nature of the Output Is Fundamentally Different
The output of an LLM is code (text). The output of an RL motor controller is neural network weights trained over hundreds of thousands of episodes in simulation. It is not a matter of "writing better code" -- it is knowledge acquired through interaction with physical environments.
3. Scalability Across Robot Models
When building controllers with code generation tools, the code must be rewritten every time the robot changes. With an RL-based approach, you simply load the new robot model in the simulator and re-train. As the number of robot models grows, this difference scales exponentially.
Key Takeaways
- High-level control (natural language to commands, task planning) is big tech's domain, with LLMs and VLAs advancing rapidly
- Low-level motor control (1kHz real-time torque output) is a domain that LLMs cannot replace
- WIM replaces PID/ADRC with RL at the low-level control layer, while retaining classical controllers as a fallback for safety
- A Sim-to-Real pipeline runs simulation training and real robot validation in parallel
- When the robot model changes, automated policy re-training handles adaptation -- a platform that eliminates manual tuning